Wer KI-Anwendungen wie z.B. eine semantische Suche erstellen will, braucht eine passende Vektordatenbank. Diese machen Embeddings blitzschnell abrufbar und skalieren besser als klassische SQL- oder NoSQL-Stores. Wir stellen beliebte Optionen von SaaS bis Open Source vor – inklusive Stärken, Kosten und typischer Use Cases.
Stell dir vor, du hast tausende Texte oder Bilder, und du möchtest auf intelligente Weise ähnliche Inhalte finden. Statt exakte Begriffe zu vergleichen, wird jeder Inhalt in einen sogenannten Vektor übersetzt – eine Art mathematischer Fingerabdruck (genannt: „Embeddings“). Diese Vektoren speichern die Bedeutung statt nur der Wörter. Ähnliche Begriffe haben auch ähnliche Vektoren, liegen also nah beieinander. Mit der Kosinus-Distanz und anderen Verfahren wird dann verglichen, wie nah z.B. eine KI-Anfrage nach „Apfel“ entfernt von anderen Vektoren für „Birne“ oder „Pferd“ entfernt sind. Obst ist näher beieinander. Vektoren bilden damit die Basis für eine perfekte Suche, egal wie der Begriff geschrieben wird. Mehr dazu lernen: Introduction to Vector Databases
Vektordatenbanken helfen dabei, diese Vektoren effizient zu speichern und in Echtzeit ähnliche zu finden – sozusagen eine Google-Suche nach Bedeutungen. Sie kommen zum Einsatz, wenn klassische Schlagwortsuche nicht mehr ausreicht – z. B. bei Chatbots, RAG-Suche in Firmendokumenten, Suchmaschinen oder Empfehlungssystemen. Artikel: So erstellst du ein RAG-System mit n8n
Übersicht: Vektordatenbanken für KI-Anwendungen
Bei der Auswahl einer passenden Vektordatenbank für KI-Projekte zählt zunächst das Lizenzmodell, denn Open-Source-Lösungen haben den Vorteil, den Code komplett unter Kontrolle zu haben und die Lösung anbieterunabhängig betreiben zu können. Auch das Hosting-Modell spielt eine Rolle: Einige Lösungen sind rein lokal installierbar, andere vollständig als Cloud-Service verfügbar. Wer eher minimalen Wartungsaufwand will, wählt besser eine in der Cloud gemanagte Lösung. Die Fähigkeit, hybride Suchen (Kombination aus Keyword- und Vektorsuche) zu unterstützen, kann für viele RAG-Szenarien entscheidend sein. Wer auf Skalierung setzt, sollte außerdem auf verteilte Architektur und GPU-Support achten. Nicht zuletzt ist die LLM-/RAG-Kompatibilität relevant – etwa durch APIs, Integrationen oder nativen Support für Tools wie LangChain oder LlamaIndex.
Einfache Integration in bestehende Redis-Infrastruktur
Pinecone – Die Cloud-native Vektor-DB
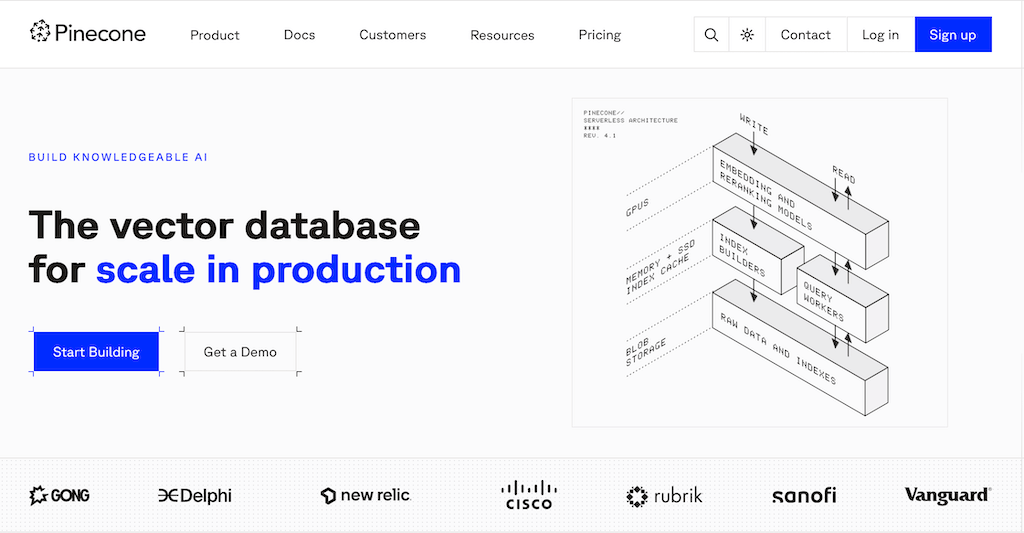
Einfach starten, nicht selbst verwalten. Pinecone ist ein vollständig gemanagter Cloud‑Dienst, bei dem du dich weder um Server noch um Sharding kümmern musst. Die serverless Architektur skaliert automatisch von wenigen Tausend bis zu Milliarden Vektoren. Ein übersichtliches Dashboard zeigt Query‑Latenzen, Speicherverbrauch und Index‑Statistiken in Echtzeit. Dank EU‑Regionen und Verschlüsselung‑at‑rest bleibt deine Lösung DSGVO‑konform. SDKs für Python, JavaScript und Go sowie Plug‑ins für LangChain, LlamaIndex und Haystack verkürzen die Time‑to‑Prod drastisch.
Kosten: Free-Tier (5 GB), ab 0,096 $/GB/Monat (Starter)
Verbreitung: sehr hoch ★★★
Besonderheiten: Voll gemanagte Skalierung, nur Vektor-SQL, DSGVO-Konformität via EU-Regionen, tiefe LLM-Integrationen (LangChain, LlamaIndex).
Geeignet für: Produktive RAG- und SemSearch-APIs ohne Infrastrukturaufwand.
Spannende Fakten:
Echtzeit-Indexierung und Skalierbarkeit: Pinecone ermöglicht Echtzeitindexierung und bietet eine vertikal skalierbare Infrastruktur, die die Vektorsuche bis zu zehnmal schneller macht als herkömmliche Methoden.
Integration in KI-Systeme: Unternehmen wie Notion nutzen Pinecone, um ihre KI-Funktionalitäten zu optimieren, was zeigt, wie breit die Anwendbarkeit ist.
Weaviate – Ein Open-Source-Allrounder
Das Motto von Weaviate ist: Semantische Suche + Graph = flexible Plattform. Weaviate läuft als einzelnes Binary im Docker‑Container oder als Cluster in Kubernetes und eignet sich daher perfekt für Self‑Hosting. Eine eingebaute Transformer‑Pipeline erzeugt wahlweise selbst Embeddings oder nutzt externe Modelle. Über das GraphQL‑Interface lassen sich semantische und relationale Abfragen elegant kombinieren. Versionierung und Vektor‑Sharding sorgen für lineare Skalierung. Die Community liefert laufend Module für RAG, Bilder und sogar multimodale Suche.
Geeignet für: Projekte, die Relation und Semantik kombinieren wollen.
Spannende Fakten:
Dynamischer Vector Index: Mit der neuesten Version können Benutzer flexibel zwischen flachen Indizes und HNSW-Indizes wechseln.
Modularer Aufbau und Cloud-Native: Weaviate ist cloud-native und modular, was es ideal für aktuelle KI-Entwicklungen macht.
Milvus – Für Large-Scale Performance
Wenn Milliarden Embeddings nötig sind. Große Unternehmen wie AT&T, Nvidia, Paypal, Walmart setzen auf die beliebte Open Source Vektordatenbank. Milvus setzt auf eine Microservice‑Architektur mit separaten Query‑, Proxy‑ und Data‑Nodes und erreicht so enorme Parallelität. IVF‑, HNSW‑ und GPU‑fähige Indexe erlauben dir, Speed und Genauigkeit fein zu justieren. Time‑Travel‑Queries machen Snapshots historischer Daten abrufbar – praktisch beim ML‑Retraining. Sharding und Tiered Storage (z. B. S3 oder MinIO) halten die Kosten auch bei Petabyte‑Größe im Griff. Milvus ist unter dem Namen „Zilliz Cloud“ auch als gehostete Variante verfügbar.
Kosten: Open Source (Apache 2.0), Zilliz Cloud ab 0 $ (Trial)
Verbreitung: hoch ★★★
Besonderheiten: IVF, HNSW, GPU-Support, Time-Travel-Queries, horizontale Skalierung über Shards.
Geeignet für: Bild-, Audio- oder Text-Korpora im Terabyte-Bereich.
Spannende Fakten:
Skalierbare Ähnlichkeitssuche: Milvus bietet eine Umgebung für Ähnlichkeitssuchen, die mit dichten und spärlichen Vektoren umgehen kann.
Einsatz im IBM-Ökosystem: Milvus wird in IBM watsonx.data als Vektorspeicher eingesetzt, was seine industrielle Anwendbarkeit zeigt.
Qdrant – Speed für die Produktiv-Umgebung
Schnell, sicher, in Rust geschrieben. Qdrant nutzt SIMD‑Optimierungen für extrem niedrige Latenzen selbst bei Streaming‑Updates. Payload‑Filtering erlaubt komplexe Filter über Metadaten ohne weiteren Datastore. Mit gRPC, REST und nativen Clients bindest du Qdrant in jedes Ökosystem ein. Ein Snapshot‑Feature sichert komplette Indizes im laufenden Betrieb. Die Roadmap bringt Hierarchical‑Clustering und disk‑basierte HNSW‑Level für sehr große Datensätze.
Geeignet für: Latenzkritische Echtzeit-Empfehlungssysteme in Produktion.
Chroma – Leichtgewicht fürs Prototyping
„Batteries included“ für LLM‑Spielwiesen. Chroma läuft in‑process innerhalb deines Python‑Scripts, sodass du keine externe Datenbank benötigst. Persistenz übernimmt DuckDB oder SQLite – ideal für lokale Experimente. Dank Simplified API reichen drei Zeilen Code, um Dokumente zu speichern und abzufragen. Eine experimentelle Sync‑Funktion repliziert deinen Store in ein Remote‑Cluster. Damit bleibt Chroma erst klein und wächst bei Bedarf mit.
Die Vektor‑Bibliothek von Meta. FAISS ist keine Server‑DB, sondern eine C++/Python‑Bibliothek, die du direkt in ML‑Pipelines einbinden. Du unterstützt GPUs, Half‑Precision und Quantisierung, wodurch riesige Datensätze in den Grafikspeicher passen. IVF+PQ oder OPQ reduzieren den Speicherbedarf zusätzlich drastisch. Da FAISS keine Netzwerk‑Schicht hat, erreichst du maximale Rohperformance – Skalierung und Persistenz baust du selbst. Viele Data‑Teams nutzen FAISS als Low‑Level‑Engine hinter eigenen APIs.
Besonderheiten: Extrem performant bei großen Datenmengen, unterstützt CPU & GPU, kein Serverbetrieb (Bibliothek, keine Datenbank), erfordert Coding-Skills.
Geeignet für: Forschung, ML-Prototyping, Custom Vektor-Suche in Python.
Redis (mit Vektorsuche) – Infrastruktur-Upgrade
Wenn du die beliebte Redis-Datenbank eh schon nutzt. Redis Stack erweitert bekannte Datenstrukturen um einen Vektor‑Datentyp mit HNSW‑Indizes. Damit kombinierst du klassische Hash‑ und Set‑Queries mit semantischer Suche in derselben Datenbank. Mit RedisGears kannst du In‑DB‑Pipelines wie Embedding‑Berechnung in Python oder JavaScript schreiben. Enterprise‑Editionen bringen Active‑Active‑Replication und RedisAI‑Module für Inference on the fly. Wer seine Infrastruktur minimal ändern will, erhält mit Redis eine schnelle Abkürzung.
Kosten: Redis Stack kostenlos, Redis Cloud je nach Plan
Verbreitung: hoch ★★★
Besonderheiten: Einfache Integration, Vektor-Support über Redis-Module (HNSW), bekanntes API-Handling, schnell im Setup.
Geeignet für: RAG & Vektorsuche in bestehender Redis-Umgebung.
Fazit: Welche Vektor-DB passt für welchen Zweck?
Die Wahl der Vektordatenbank hängt stark vom Reifegrad deines Projekts ab:
Du willst SaaS & sofort loslegen? → Pinecone.
Maximale Flexibilität & Open Source? → Weaviate oder Qdrant.
Petabyte-Ambitionen? → Milvus.
Einfach mal testen? → Chroma.
Selber bauen oder Redis erweitern? → FAISS oder Redis.
Tipp zum starten: Teste die Datenbank kurz mit deinem Datensatz an. Achte dabei auf Latenz, Durchsatz und natürlich die Kosten – dann steht performanten KI-Anwendungen nichts mehr im Weg.
Häufige Fragen: Vektor-Datenbanken
Eine Vektordatenbank speichert Embeddings und ermöglicht semantische Ähnlichkeitssuche. Mehr zur Funktionsweise.
Anders als klassische relationale Datenbanken mit Tabellen und Schlüsselwerten arbeitet eine Vektordatenbank mit semantischen Ähnlichkeitsvergleichen im Vektorraum. Zur Erklärung bei Elastic.
Einbettungen (Embeddings) sind Vektorrepräsentationen von z. B. Texten oder Bildern, die semantische Informationen abbilden. IBM erklärt Embeddings.
Sie ermöglichen semantische Suche, RAG-Chatbots, Personalisierung und unstrukturierte KI-Anwendungen. Beispiel: RAG erklärt.
Bei semantischer Suche wird nach Bedeutung gesucht – nicht nur nach exakten Schlüsselwörtern. Wikipedia: Semantic Search.
Zu den beliebtesten zählen Pinecone, Weaviate, Milvus, Qdrant, Chroma und FAISS. Zur Milvus-Dokumentation.
Ja – etwa für Retrieval-Augmented Generation (RAG), bei dem Vektoren als Kontext für Sprachmodelle dienen. NVIDIA erklärt RAG.
Kosinus misst Winkelähnlichkeit, Euklid misst Abstand – beide vergleichen Vektoren unterschiedlich. Mehr zu Cosine Similarity.
Ja, viele Datenbanken (z. B. Qdrant, Weaviate) liefern Ergebnisse in Millisekunden. Qdrant Performance Docs.
Ralf Schukay liebt Analytics, Python & alles mit Daten. In seiner Freizeit spielt er Synthesizer (Nord, Novation), joggt und fährt Gravel Bike. Er arbeitet als Teamlead Analytics & Conversion mit einem fitten und netten Team in der Berliner Digitalagentur >MAI mediaworx<
Wir verwenden Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wir tun dies, um das Surferlebnis zu verbessern und um personalisierte Werbung anzuzeigen. Wenn Sie diesen Technologien zustimmen, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn Sie Ihre Zustimmung nicht erteilen oder zurückziehen, können bestimmte Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.

 Das Motto von Weaviate ist: Semantische Suche + Graph = flexible Plattform. Weaviate läuft als einzelnes Binary im Docker‑Container oder als Cluster in Kubernetes und eignet sich daher perfekt für Self‑Hosting. Eine eingebaute Transformer‑Pipeline erzeugt wahlweise selbst Embeddings oder nutzt externe Modelle. Über das GraphQL‑Interface lassen sich semantische und relationale Abfragen elegant kombinieren. Versionierung und Vektor‑Sharding sorgen für lineare Skalierung. Die Community liefert laufend Module für RAG, Bilder und sogar multimodale Suche.
Das Motto von Weaviate ist: Semantische Suche + Graph = flexible Plattform. Weaviate läuft als einzelnes Binary im Docker‑Container oder als Cluster in Kubernetes und eignet sich daher perfekt für Self‑Hosting. Eine eingebaute Transformer‑Pipeline erzeugt wahlweise selbst Embeddings oder nutzt externe Modelle. Über das GraphQL‑Interface lassen sich semantische und relationale Abfragen elegant kombinieren. Versionierung und Vektor‑Sharding sorgen für lineare Skalierung. Die Community liefert laufend Module für RAG, Bilder und sogar multimodale Suche.