Llama 4 von Meta definiert durch innovative Mixture-of-Experts-Architektur, native Multimodalität und erweiterte Kontextfenster neue Maßstäbe in der künstlichen Intelligenz.
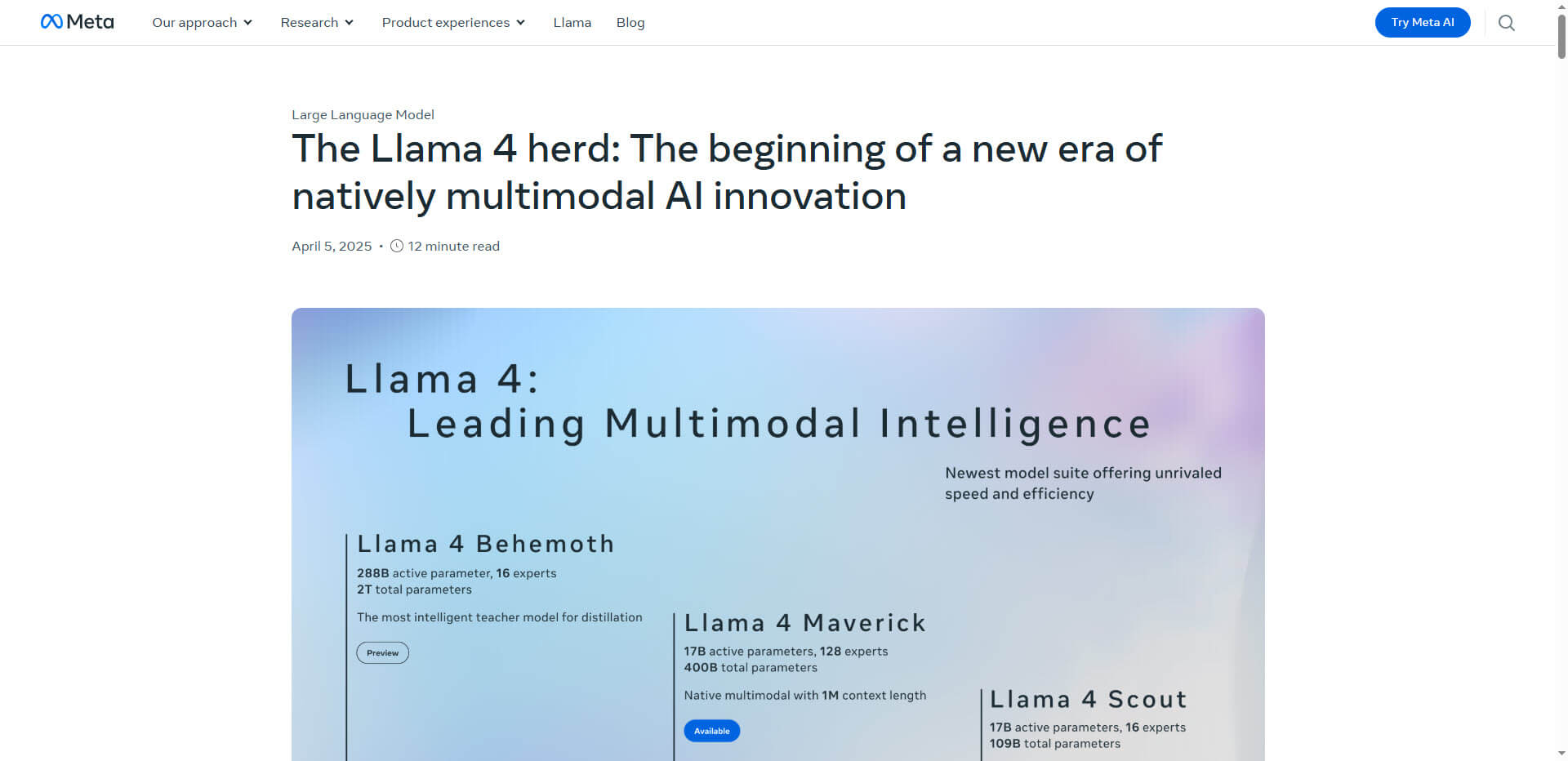
Die neueste KI-Familie von Meta – bestehend aus den Modellen Scout, Maverick und dem noch unveröffentlichten Behemoth – adressiert drei zentrale Herausforderungen moderner KI-Systeme: Recheneffizienz, multimodale Verarbeitung und Kontextlimitierungen. Mit einer revolutionären Mixture-of-Experts-Architektur (MoE) aktiviert Llama 4 nur 2-5% seiner Parameter pro Token, was die Rechenkosten drastisch reduziert, während die Leistung mit deutlich größeren Modellen mithalten kann.
Llama 4 Modelle
Der Maverick-Variante gelingt es, aus einem Pool von 400 Milliarden Parametern nur 17 Milliarden pro Anfrage zu aktivieren, was eine 95% höhere Recheneffizienz im Vergleich zu konventionellen Modellen ermöglicht.
Besonders bemerkenswert ist Llama 4s Ansatz zur multimodalen Verarbeitung. Anders als frühere Modelle, die Text- und Bilddaten getrennt verarbeiten, nutzt Llama 4 eine Early-Fusion-Methode, die verschiedene Modalitäten bereits auf Eingabeebene integriert. Durch einen MetaCLIP-basierten Vision-Encoder und spezielle Cross-Modal-Attention-Mechanismen kann das Modell komplexe Aufgaben der visuellen Sprachverarbeitung mit bemerkenswerter Genauigkeit bewältigen.
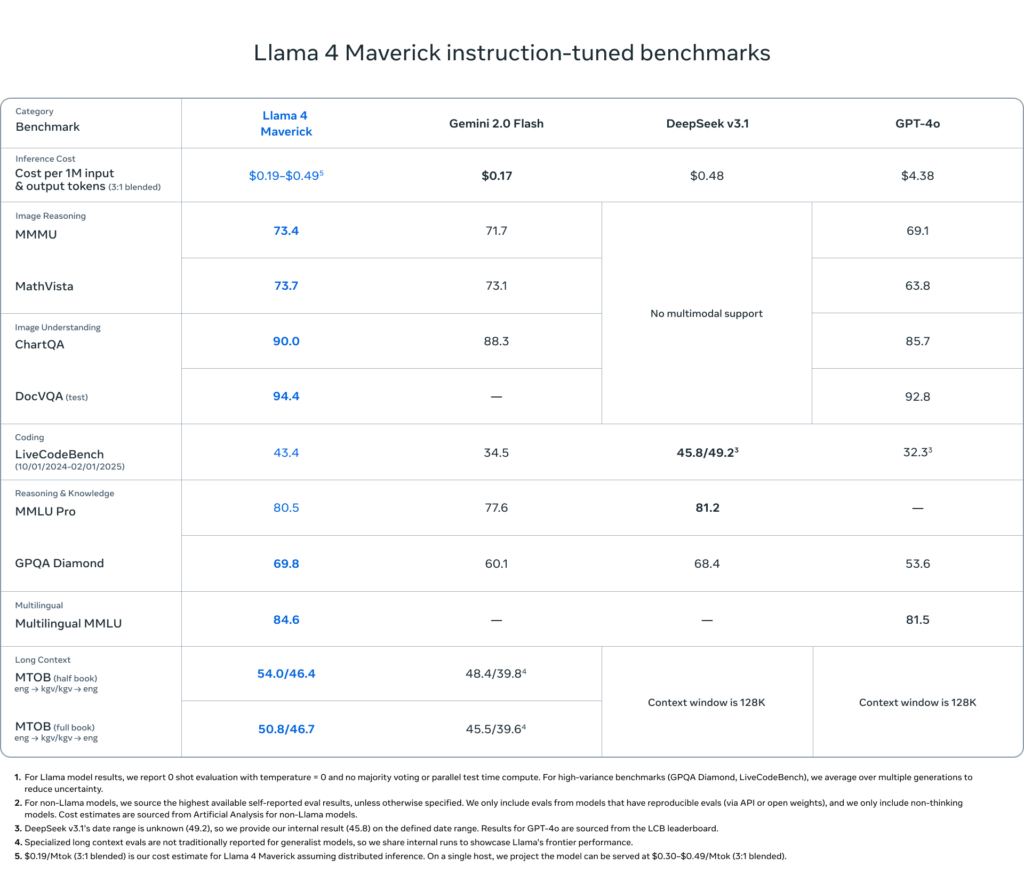
Llama 4 Maverick instruction-tuned benchmarks
Die Modelle wurden mit über 30 Billionen Token multimodaler Daten trainiert und können bis zu 48 Bilder gleichzeitig verarbeiten – eine Fähigkeit, die insbesondere für Anwendungen in der Bildanalyse und bei dokumentenbasierten Anfragen relevant ist.
Das Scout-Modell beeindruckt zudem mit einem 10-Millionen-Token-Kontextfenster, das durch die innovative iRoPE-Architektur (Interleaved Rotary Position Embedding) ermöglicht wird. Diese Technologie erlaubt es dem Modell, umfangreiche Dokumente zu verarbeiten und dabei sowohl lokale als auch globale Zusammenhänge zu erfassen. Benchmarks zeigen eine 98% Abrufgenauigkeit bei 10 Millionen Token umfassenden Codebasen.
Zusammenfassung:
Llama 4 nutzt eine Mixture-of-Experts-Architektur, die nur 2-5% der Parameter pro Anfrage aktiviert und dadurch die Recheneffizienz um 95% steigert
Native multimodale Verarbeitung durch Early-Fusion ermöglicht die gleichzeitige Verarbeitung von bis zu 48 Bildern
10 Millionen Token Kontextfenster übertrifft GPT-4 um das 80-fache und ermöglicht die Analyse umfangreicher Dokumente
Leistungsvergleiche zeigen Überlegenheit gegenüber GPT-4o und Gemini 2.0 bei gleichzeitiger Reduzierung des Energieverbrauchs um 40%
Erste Enterprise-Integrationen bei Snowflake und Cloudflare demonstrieren praktische Anwendungsfälle in der Dokumentenanalyse und Echtzeit-Bildverarbeitung
Florian Schröder ist Experte im Online-Marketing mit Schwerpunkt PPC (Pay-Per-Click) Kampagnen. Die revolutionären Möglichkeiten der KI erkennt er nicht nur, sondern hat sie bereits fest in seine tägliche Arbeit integriert, um innovative und effektive Marketingstrategien zu entwickeln.
Er ist überzeugt davon, dass die Zukunft des Marketings untrennbar mit der Weiterentwicklung und Nutzung von künstlicher Intelligenz verbunden ist und setzt sich dafür ein, stets am Puls dieser technologischen Entwicklungen zu bleiben.
Wir verwenden Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wir tun dies, um das Surferlebnis zu verbessern und um personalisierte Werbung anzuzeigen. Wenn Sie diesen Technologien zustimmen, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn Sie Ihre Zustimmung nicht erteilen oder zurückziehen, können bestimmte Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.