Mit der Veröffentlichung von Llama 3.2-Vision setzt Meta einen neuen Maßstab in der Welt der multimodalen Künstlichen Intelligenz. Diese Modelle bieten umfassende Lösungen, die Text- und Bildinformationen nahtlos integrieren und damit weitreichende Einsatzmöglichkeiten für Entwickler und Unternehmen eröffnen.
Unter dem Namen Llama 3.2-Vision stellt Meta Modelle in zwei Größen, mit 11 Milliarden und 90 Milliarden Parametern, vor. Sie sind speziell für Aufgaben optimiert, die sowohl Text als auch Bilder erfordern. Diese Modelle verbinden die Llama 3.1 Sprachfähigkeiten mit neuen visuellen Erkennungs- und Bilderklärungsoptionen, indem sie eine separat trainierte Vision-Adapter verwenden. Mit der Nutzung von Supevised Fine-Tuning (SFT) und Reinforcement Learning with Human Feedback (RLHF) wird sichergestellt, dass die Modelle den menschlichen Vorlieben in Bezug auf Hilfsbereitschaft und Sicherheit entsprechen.
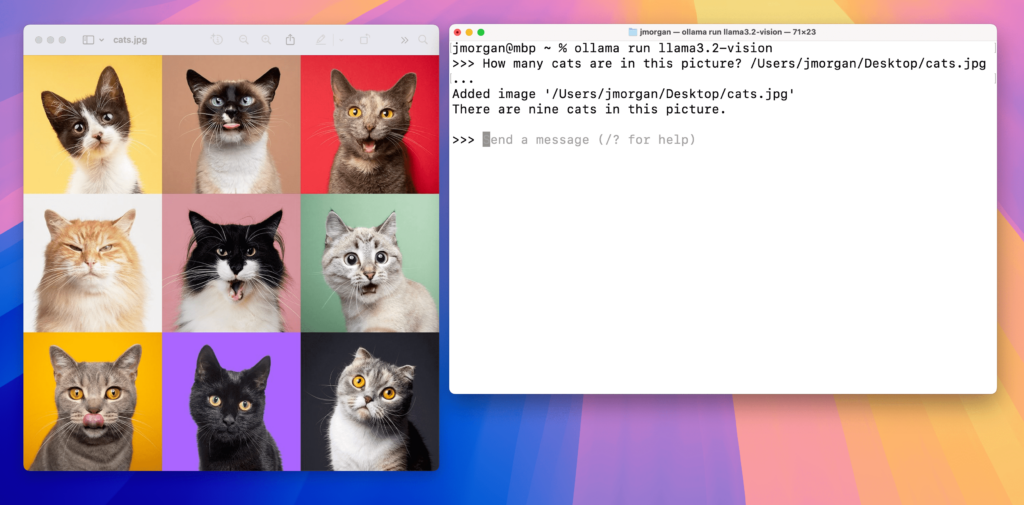
Llama3.2 Vision: Image Q&A ; Source: Ollama
Die Bandbreite der Anwendungen umfasst Bildunterschriftenerstellung, bei der die Modelle in der Lage sind, Szenen zu verstehen und passende Beschreibungen zu generieren, sowie Bild-Text-Abfragen, was einer Suchmaschine gleicht, die sowohl Bild- als auch Textinformationen versteht. Die Fähigkeit zur visuellen Fundamentierung ermöglicht es den Modellen, bestimmte Objekte oder Bereiche in einem Bild anhand von natürlichen Sprachbeschreibungen zu identifizieren.
Eine bemerkenswerte Innovation von Meta ist die Integration der Modelle in Edge- und Mobilgeräte. Partnerschaften mit Unternehmen wie Arm, MediaTek und Qualcomm spielen hierbei eine zentrale Rolle, um leistungsstarke KI auf Geräten bereitzustellen, die über begrenzte Rechenressourcen verfügen. Dies ermöglicht Entwicklern, Anwendungen zu erstellen, die im Alltag weit verbreitet sind. Die Community-Lizenz von Llama 3.2 bietet die Möglichkeit sowohl kommerzieller als auch wissenschaftlicher Nutzung und öffnet die Türen für Anwendungen in der Daten- und Modellentwicklung.
Die Veröffentlichung der Llama 3.2-Vision-Modelle stellt einen bedeutenden Schritt in der KI-Forschung dar. Der Vorteil multimodaler Modelle liegt in ihrer Fähigkeit, die Kluft zwischen verschiedenen Datenformen zu überbrücken und somit vielseitige und flexible Lösungen zu bieten. Diese Weiterentwicklung untermauert die Relevanz von KI in Bereichen wie Bildung, Design und Medizin, wo sowohl Bild- als auch Sprachverstehen wichtig sind.
Die wichtigsten Fakten zum Update:
Llama 3.2-Vision bietet Modelle in zwei Größen: 11 und 90 Milliarden Parameter.
Anwendungsgebiete umfassen Bildunterschriftenerstellung und visuelle Fundamentierung.
Modelle profitieren von Supervised Fine-Tuning und Reinforcement Learning with Human Feedback.
Integration in Edge- und Mobilgeräte durch Partnerschaften mit führenden Herstellern.
Community-Lizenz fördert kommerzielle und wissenschaftliche Anwendungen.
Dieses Update signalisiert einen bedeutenden Wandel in der Vielzahl der Möglichkeiten, die KI in Zukunft nutzen kann, und regt zur Diskussion über das immense Potenzial multimodaler Modelle an.
Florian Schröder ist Experte im Online-Marketing mit Schwerpunkt PPC (Pay-Per-Click) Kampagnen. Die revolutionären Möglichkeiten der KI erkennt er nicht nur, sondern hat sie bereits fest in seine tägliche Arbeit integriert, um innovative und effektive Marketingstrategien zu entwickeln.
Er ist überzeugt davon, dass die Zukunft des Marketings untrennbar mit der Weiterentwicklung und Nutzung von künstlicher Intelligenz verbunden ist und setzt sich dafür ein, stets am Puls dieser technologischen Entwicklungen zu bleiben.
Wir verwenden Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wir tun dies, um das Surferlebnis zu verbessern und um personalisierte Werbung anzuzeigen. Wenn Sie diesen Technologien zustimmen, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn Sie Ihre Zustimmung nicht erteilen oder zurückziehen, können bestimmte Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.