KI-Workflows für Marketer mit n8n bezeichnet automatisierte, Node-basierte Datenpipelines zur Orchestrierung von Marketing-APIs, Scrapern und Large Language Models, was die effiziente und kostengünstige Skalierung mehrstufiger Content-Prozesse direkt in CMS-Systeme ermöglicht.
Das Self-Hosting von n8n bezeichnet den Betrieb der lizenzgebührenfreien Community Edition auf einem eigenen Server und bietet Marketern unbegrenzte Workflow-Ausführungen — bei minimalen Server-Kosten von lediglich 5 bis 10 € pro Monat statt des Cloud-Starter-Limits von 2.500 Executions.
Kostenoptimierung in Daten-Loops: Nutzen Sie die native JSON-Array-Verarbeitung von n8n, um API-Kosten bei Massen-Abfragen drastisch zu senken — ein Workflow zur Analyse von 50 URLs kostet bei n8n exakt eine einzige Execution, während Make.com dafür 201 kostenpflichtige Operations abrechnet.
Hybrid-Modell für LLM-Content: Optimieren Sie das Kosten-Qualitäts-Verhältnis, indem Sie Gemini 3.5 Flash für die günstige SERP-Recherche (Kontextfenster: 1.000.000 Token für 0,50 $ pro 1M Input-Token) einsetzen und die finale Texterstellung an Claude 3.5 Sonnet (15,00 $ pro 1M Output-Token) übergeben.
Fehlerminimierung beim WordPress-Upload: Sichern Sie Ihre automatisierten Veröffentlichungen ab, indem Sie den Artikel-Status im WordPress-Node zwingend auf „draft“ setzen und n8n-IPs in der Web-Application-Firewall (WAF) whitelisten, um blockierte POST-Requests (403-Fehler) zu verhindern.
KI-Workflows für Marketer mit n8n: Die wichtigsten Infos
Die Workflow-Plattform n8n etabliert sich als führender Orchestrator für KI-gestütztes Marketing, indem sie Web-Scraper, Large Language Models wie Google Gemini und CMS-Systeme flexibel verbindet. Im Gegensatz zu Make.com oder Zapier rechnet n8n nicht pro Einzelschritt ab, sondern pro vollständigem Durchlauf, was bei komplexen Daten-Loops massive Kostenvorteile bringt. Mit der kostenfreien Community Edition lässt sich das System zudem komplett selbst hosten, wodurch teure Lizenzgebühren entfallen und die volle Datensouveränität gewahrt bleibt.
Für Dein Business bedeutet das eine Kostenersparnis von bis zu 90 Prozent bei der automatisierten Inhaltserstellung im Vergleich zu herkömmlichen No-Code-Tools. Durch die direkte Integration von Live-Konkurrenzdaten via Schnittstellen hebst Du die Qualität Deines Contents auf ein neues Niveau, ohne wertvolle Arbeitszeit für manuelle Recherchen zu verschwenden.
Starte morgen, indem Du eine n8n-Instanz auf einem günstigen VPS-Server für rund fünf Euro im Monat aufsetzt, um unbegrenzte Workflows ohne künstliche Limits auszuführen. Verknüpfe im Editor ein kostengünstiges Modell wie Gemini 3.5 Flash für die Datenanalyse mit Claude 3.5 Sonnet für die finale, natürlich klingende Texterstellung. Konfiguriere den WordPress-Node abschließend zwingend so, dass generierte Artikel als „Draft“ (Entwurf) hochgeladen werden, um ein manuelles Review als finale Qualitätskontrolle zu sichern.
n8n revolutioniert KI-Workflows für Marketer mit n8n, die als automatisierte Prozesse zur SEO-Analyse und Inhaltserstellung mittels Google Gemini die Redaktionskosten durch extrem niedrige API-Preise von nur 0,50 US-Dollar pro Million Tokens radikal senken. Während restriktive SaaS-Modelle oft an engen Limits von 2.500 monatlichen Ausführungen scheitern, bietet das Self-Hosting-Setup unbegrenzte Skalierbarkeit für datenintensive SEO-Kampagnen. In dieser Analyse zeigen wir, wie Sie typische IP-Blockaden in WordPress umgehen, n8n direkt mit Make.com vergleichen und den Agenten-Workflow „Keywordo-kun“ fehlerfrei aufsetzen.
Was sind KI-Workflows für Marketer mit n8n? (Definition & Grundlagen)
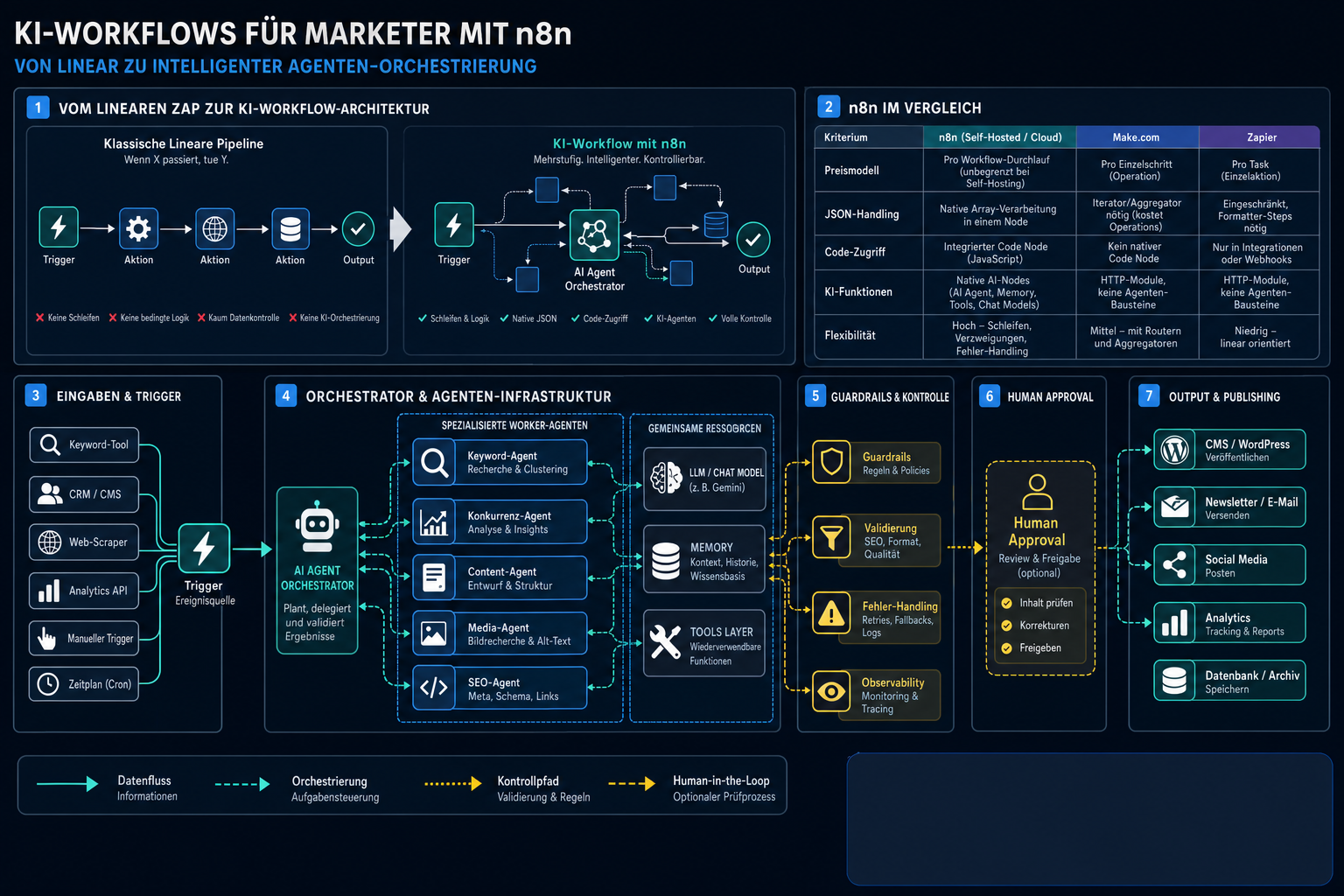
Visualisierung zum Abschnitt: Was sind KI-Workflows für Marketer mit n8n? (Definition & Grundlagen)
Ein KI-Workflow für Marketer mit n8n ist eine automatisierte, node-basierte Datenpipeline, die Marketing-APIs, Web-Scraper und Large Language Models wie Google Gemini in einer visuellen Oberfläche verknüpft. Im Unterschied zu linearen Trigger-Aktionen erlaubt n8n komplexe Logikschleifen, native JavaScript-Datenbereinigung und die direkte Integration von KI-Agenten – bis hin zur vollautomatischen Veröffentlichung in WordPress.
Warum „KI-Workflow“ mehr ist als ein Zapier-Zap
Der Begriff klingt austauschbar, ist es aber nicht. Klassische Automatisierungstools wie Zapier oder IFTTT arbeiten nach dem Prinzip „Wenn X passiert, tue Y“. Das reicht für Slack-Benachrichtigungen oder CRM-Updates. Sobald Marketing-Teams aber mehrstufige Content-Pipelines aufbauen wollen – Keyword-Recherche, Konkurrenzanalyse, Artikelgenerierung, Bildrecherche, SEO-Metadaten, CMS-Publishing – stößt dieses lineare Modell an harte Grenzen.
n8n löst das durch drei strukturelle Vorteile:
Native JSON-Verarbeitung: n8n verarbeitet komplexe JSON-Arrays in einem einzigen Node. Make.com benötigt dafür separate Iterator- und Aggregator-Nodes, die jeweils als eigene Operations abgerechnet werden.
Voller Code-Zugriff: Ein integrierter Code Node erlaubt JavaScript direkt im Workflow-Editor – etwa zur Bereinigung von LLM-Ausgaben, bevor sie an WordPress gehen.
Dedizierte AI-Nodes: n8n bietet native Komponenten für KI-Agenten (AI Agent Node, Tools Agent), Chat Models, Memory Sub-Nodes und Tool Nodes. Das sind keine generischen HTTP-Requests, sondern spezialisierte Bausteine für Agenten-Orchestrierung.
Kriterium
n8n (Self-Hosted / Cloud)
Make.com
Zapier
Preismodell
Pro Workflow-Durchlauf (unbegrenzt bei Self-Hosting)
Pro Einzelschritt (Operation)
Pro Task (Einzelaktion)
JSON-Handling
Native Array-Verarbeitung in einem Node
Iterator/Aggregator nötig (kostet Operations)
Eingeschränkt, Formatter-Steps nötig
Code-Integration
JavaScript/Python direkt im Editor
Eingeschränkt, oft externe Functions nötig
Nur über Code by Zapier (limitiert)
AI-Native Nodes
AI Agent, Memory, Vector Store, Tool Nodes
Klassische API-Mappings
Keine dedizierten AI-Agenten-Nodes
Self-Hosting
Ja (Community Edition, 0 € Lizenz)
Nein
Nein
n8n als Orchestrator für generative KI im Marketing
Der entscheidende Punkt: n8n ist kein Content-Generator. Es ist der Orchestrator, der alle Teile einer KI-gestützten Marketing-Pipeline zusammenhält. Das Tool selbst schreibt keinen Text – es steuert, welche Daten wann an welches LLM gehen, wie die Antwort nachbearbeitet wird und wohin der Output fließt.
Konkret bedeutet das für einen SEO-Blog-Workflow:
Trigger: Ein Webhook empfängt ein Fokus-Keyword aus Airtable oder Google Sheets.
Enrichment: Ein HTTP Request Node holt SERP-Daten über eine API wie DataForSEO oder SerpAPI. Ein weiterer Node scrapt Konkurrenzseiten via Firecrawl.
Synthese: Ein Google Gemini Chat Model Node erhält die aggregierten Daten als Kontext und generiert den Artikel.
Nachbearbeitung: Ein Code Node bereinigt die LLM-Ausgabe – etwa das typische Einpacken in Markdown-Code-Blöcke.
Publishing: Ein WordPress Node sendet den fertigen Entwurf per REST-API ans CMS, inklusive Meta-Title, Meta-Description und Bild-Alt-Tags.
Die JSON-Schnittstelle zwischen den Nodes ist dabei das Rückgrat. Jeder Node gibt strukturierte JSON-Objekte aus, die der nächste Node direkt konsumieren kann. Das macht n8n besonders stark bei der Übergabe von Rohdaten an LLM-Prompts – etwa wenn Konkurrenz-Markdown, Keyword-Daten und Marken-Guidelines in einem einzigen Prompt-Template zusammenfließen.
Datenkontrolle: Self-Hosted vs. Cloud
Für Marketing-Teams mit sensiblen Kundendaten oder strengen Compliance-Anforderungen ist die Self-Hosting-Option ein echtes Differenzierungsmerkmal. Die n8n Community Edition läuft auf einem günstigen VPS – laut Community-Berichten stabil ab etwa 5 $ pro Monat auf Anbietern wie Hetzner oder PikaPods. Keine Lizenzgebühr, unbegrenzte Workflow-Ausführungen.
Der Trade-off: Kein natives Team-Sharing von Workflows, kein SSO/LDAP, keine globalen Variablen über die UI. Wer im Team arbeitet, braucht entweder die Cloud-Variante oder baut sich eigene Workarounds.
Wo die Grenzen liegen
KI-Workflows für Marketer mit n8n sind kein Autopilot. Drei reale Probleme aus der Praxis:
LLM-Tonalität:Gemini-Modelle schreiben ohne intensives Prompt-Engineering oft repetitiv und robotisch. Wer Corporate-Blog-Qualität erwartet, muss erheblich in Prompt-Tuning investieren – oder auf Claude als Alternative setzen, das bei natürlicher Sprache stärker performt.
WordPress-Firewall-Blockaden: Shared-Hosting-Anbieter blockieren n8n-Cloud-IPs regelmäßig über WAFs wie ModSecurity oder Plugins wie Wordfence. Das Ergebnis: 403 Forbidden oder 429 Too Many Requests beim POST an die REST-API.
Halluzinationsrisiko: Automatisch generierte SEO-Inhalte müssen vor der Veröffentlichung geprüft werden. Der Status draft im WordPress Node ist keine optionale Sicherheitsmaßnahme – er ist Pflicht.
n8n Workflow-Automatisierung für Marketing-Teams
n8n vs. Make.com: Die richtige Automatisierungs-Plattform für Marketer
Für KI-Workflows für Marketer mit n8n ist n8n die technisch überlegene Wahl gegenüber Make.com. Der entscheidende Unterschied liegt im Abrechnungsmodell: n8n rechnet pro vollständigem Workflow-Durchlauf (Execution) ab, Make.com pro Einzelschritt (Operation). Bei datenintensiven Marketing-Pipelines mit Schleifen über Artikel-Listen, Keyword-Sets oder Produkt-Feeds führt das bei Make.com zu exponentiell steigenden Kosten – während n8n exakt eine Execution berechnet.
Quick Answer: n8n oder Make.com für KI-Pipelines?
n8n ist für komplexe KI-Pipelines kosteneffizienter und technisch flexibler. Die Self-Hosted Community Edition läuft unbegrenzt auf einem günstigen VPS. Zudem bietet n8n dedizierte Advanced-AI-Nodes für Agenten, Memory und Vector Stores sowie volle JavaScript/Python-Integration direkt im Editor – Features, die Make.com nur über Umwege oder externe Services abbilden kann.
Der vollständige Plattformvergleich
Kriterium
n8n (SaaS / Cloud)
n8n (Self-Hosted CE)
Make.com
Abrechnungsmodell
Pro erfolgreichem Workflow-Durchlauf (Execution)
Komplett kostenfreie Community Edition
Pro Einzelschritt (Operation)
Kosten
Ab 24 €/Monat (2.500 Executions)
0 € Lizenzgebühr (zzgl. VPS-Hosting ca. 5–10 €/Monat)
Stark eingeschränkt, oft externe Serverless Functions nötig
AI-Native Features
Dedizierte Nodes für AI Agent, Memory, Vector Stores, Tool Nodes
Dedizierte Nodes für AI Agent, Memory, Vector Stores, Tool Nodes
Hauptsächlich Standard-API-Mapping
Max. gleichzeitige Ausführungen
5 (Starter) / 20 (Pro)
Nur durch Server-Ressourcen begrenzt
Abhängig vom Tarif
Das Operations- vs. Executions-Paradoxon im Marketing
Hier wird der Kostenunterschied greifbar: Ein typischer Content-Workflow holt 50 Artikel-URLs aus einem Google Sheet, scrapt jede Seite, schickt den Content an Google Gemini zur Analyse und schreibt die Ergebnisse zurück.
Bei Make.com sieht die Rechnung so aus:
1 Operation für den Google-Sheets-Trigger
50 Operationen für den Iterator über die 50 Zeilen
50 Operationen für 50 HTTP-Requests (Scraping)
50 Operationen für 50 Gemini-API-Calls
50 Operationen für 50 Rückschreibe-Aktionen
Summe: 201 Operations für einen einzigen Workflow-Durchlauf
Bei n8n kostet derselbe Vorgang exakt eine Execution – egal ob 50 oder 500 Elemente in der Schleife verarbeitet werden. n8n verarbeitet JSON-Arrays nativ innerhalb eines Nodes, ohne dass jedes Element als separater Abrechnungsschritt zählt.
Für Marketer, die regelmäßig Keyword-Listen, Produkt-Feeds oder Content-Audits durch KI-Pipelines jagen, ist dieser Unterschied der zentrale Kostenfaktor.
Das n8n-SaaS-Preisschock-Szenario
Aber auch n8n Cloud hat Fallstricke. Der Starter-Tarif mit 2.500 Ausführungen pro Monat klingt großzügig – bis Polling-Trigger ins Spiel kommen. Ein stündlicher RSS-Feed-Check verbraucht allein 720 Executions pro Monat (24 × 30). Drei solcher Trigger, und das monatliche Budget ist aufgebraucht, bevor ein einziger produktiver Workflow gelaufen ist.
Praxis-Tipp: Polling-Trigger in n8n Cloud auf das absolute Minimum reduzieren. Wo möglich, auf Webhook-basierte Trigger umstellen – die lösen nur bei tatsächlichen Events aus und verbrauchen keine Executions im Leerlauf.
Self-Hosted vs. Cloud: Wann sich ein 5-€-VPS für n8n rentiert
Die Self-Hosted Community Edition (CE) eliminiert das Execution-Limit komplett. Ein VPS bei Hetzner (CX22) oder ein Managed-Setup über PikaPods kostet unter 10 € pro Monat und liefert unbegrenzte Workflow-Ausführungen.
Die Trade-offs sind real:
Keine native Multi-User-Kollaboration in der kostenlosen CE – jeder Nutzer arbeitet in seinem eigenen Silo
Keine globalen Variablen/Secrets auf UI-Ebene – API-Keys müssen pro Workflow oder über Umgebungsvariablen auf Server-Ebene verwaltet werden
Kein SSO/LDAP – für größere Teams mit Compliance-Anforderungen ein Ausschlusskriterium
Wartungsaufwand: Updates, Backups und SSL-Zertifikate liegen in eigener Verantwortung
Die Faustregel: Wer mehr als 5 aktive Workflows mit regelmäßigen Triggern betreibt, fährt mit Self-Hosting fast immer günstiger. Wer ein Team mit mehr als zwei Personen koordinieren muss und keine DevOps-Kapazität hat, ist mit n8n Cloud Pro (60 €/Monat, 10.000 Executions) besser bedient.
Wann Make.com trotzdem Sinn ergibt
Make.com hat eine deutlich flachere Lernkurve und einen visuellen Editor, der für einfache Workflows ohne Code-Bedarf schneller zum Ergebnis führt. Für lineare Automatisierungen ohne Schleifen – etwa „Neuer Lead in HubSpot → Slack-Nachricht → Google Sheet“ – ist Make.com völlig ausreichend und schneller aufgesetzt. Sobald aber JSON-Manipulation, Code Nodes oder AI-Agent-Orchestrierung ins Spiel kommen, stößt Make.com an strukturelle Grenzen.
n8n Workflow-Automatisierung für Einsteiger
Der „Keywordo-kun“ SEO-Generator: Ein End-to-End Tutorial
Der „Keywordo-kun“ ist ein zweistufiger n8n-Workflow, der als autonomer SEO-Redakteur arbeitet. Er nimmt ein Fokus-Keyword entgegen, scrapt die Top-Konkurrenten via SERP-API und Firecrawl, lässt Google Gemini einen optimierten Artikel samt Meta-Daten generieren, bereinigt den LLM-Output per JavaScript-Node und lädt den fertigen Entwurf direkt über die WordPress REST-API als Draft hoch.
Dieser Workflow basiert auf einem real existierenden Agenten-Pattern, das in der n8n-Community unter dem Namen „Keywordo-kun“ dokumentiert ist. Die Pipeline zeigt exemplarisch, wie KI-Workflows für Marketer mit n8n von der Keyword-Eingabe bis zum WordPress-Draft vollständig automatisiert ablaufen – ohne manuellen Zwischenschritt.
Die Architektur im Überblick
Der Workflow besteht aus fünf Nodes, die linear verkettet sind:
Jeder Node hat eine klar definierte Aufgabe. Fehler in einem Schritt brechen den gesamten Workflow ab – deshalb ist die Reihenfolge und die Datenbereinigung zwischen den Nodes entscheidend.
Schritt 1: Keyword-Trigger und SERP-Datenextraktion
Der Einstieg erfolgt über einen Webhook-Node. Dieser empfängt das Fokus-Keyword als JSON-Payload – ausgelöst durch eine Airtable-Zeile, ein Google-Sheets-Update oder einen manuellen API-Call.
Live-Wettbewerber-Recherche: Ein HTTP-Request-Node fragt die DataForSEO-API oder SerpAPI ab, um die Top-3 rankenden URLs für das Fokus-Keyword zu extrahieren. Wichtig: Nur die organischen Ergebnisse werden geparsed, keine Ads oder Featured Snippets.
HTML-to-Markdown-Scraping: Die extrahierten URLs werden an Firecrawl übergeben. Firecrawl konvertiert das HTML der Konkurrenzseiten in sauberes Markdown – ohne JavaScript-Artefakte, Cookie-Banner oder Werbung. Das Ergebnis ist ein kompakter Text-Input, den das LLM effizient verarbeiten kann, ohne Token auf irrelevanten HTML-Ballast zu verschwenden.
Schritt 2: Deep Context-Generierung mit Google Gemini
Modellauswahl: Für diesen Workflow eignet sich Gemini 3.5 Flash optimal. Bei einem Preis von 0,50 $ pro 1M Input-Token und 3,00 $ pro 1M Output-Token bleibt die Generierung selbst bei hunderten Artikeln pro Monat im niedrigen einstelligen Dollarbereich. Das Kontextfenster von 1.000.000 Token reicht locker, um drei vollständige Konkurrenz-Artikel plus Prompt-Anweisungen zu verarbeiten.
Der System-Prompt ist das Herzstück der Content-Qualität. Er muss das LLM zwingen, strukturiertes JSON statt freies Markdown auszugeben:
Du bist ein erfahrener SEO-Redakteur. Schreibe einen umfassenden, strukturierten Artikel basierend auf folgenden Konkurrenz-Daten (Markdown): {{ $json.competitor_markdown }}.
Fokus-Keyword: {{ $json.keyword }}
Anweisungen:
- Nutze semantische HTML-Tags (<h2>, <h3>, <p>, <ul>, <li>).
- Integriere das Keyword natürlich in H2 und im ersten Absatz.
- Generiere zusätzlich einen optimierten SEO-Title (max. 60 Zeichen) und eine Meta-Description (max. 155 Zeichen).
- WICHTIG: Antworte ausschließlich im JSON-Format mit den Keys: "title", "content", "meta_title", "meta_description". Gib kein Markdown-Code-Wrapper (wie ```json ... ```) aus!
Kritischer Hinweis zur Tonalität: Gemini-Modelle schreiben ohne explizite Stilanweisungen spürbar „robotisch“ und repetitiv. Wer natürlichere Texte braucht, sollte im Prompt konkrete Stilbeispiele mitgeben oder für hochwertige Corporate-Blogs Gemini Pro mit höherer Output-Qualität einsetzen – bei entsprechend höheren Kosten von 2,00 $ pro 1M Input-Token.
Schritt 3: Der Code-Node zur HTML- und JSON-Bereinigung
Das Problem ist real: LLMs packen JSON-Antworten zuverlässig in Markdown-Codeblöcke ein – trotz expliziter Anweisung dagegen. Das führt beim WordPress-Upload zu kaputtem HTML im Editor. Ein nachgeschalteter Code-Node in n8n löst das:
Praxis-Tipp: Wrappen Sie den JSON.parse()-Aufruf zusätzlich in einen try/catch-Block. Wenn Gemini trotzdem invalides JSON liefert, kann der Workflow einen Retry-Loop auslösen statt komplett abzubrechen.
Schritt 4: Übergabe an die WordPress REST-API
Authentifizierung: WordPress Application Passwords (Standard seit WP 5.6) über HTTPS Basic Auth sind die stabilste Methode. Kein Plugin nötig, keine OAuth-Komplexität.
Der POST-Request geht an /wp-json/wp/v2/posts mit folgendem Payload:
Parameter
Wert
Zweck
title
{{ $json.title }}
Artikeltitel aus Gemini-Output
content
{{ $json.clean\_content }}
Bereinigtes HTML aus Code-Node
status
draft
Sicherheitsmaßnahme für manuelles Review
meta._yoast_wpseo\_metadesc
{{ $json.meta\_description }}
Meta-Description direkt an Yoast SEO übergeben
meta._yoast_wpseo\_title
{{ $json.meta\_title }}
SEO-Title direkt an Yoast SEO übergeben
Bekannte Stolperfalle: Shared-Hosting-Anbieter blockieren n8n-Cloud-IPs häufig über WAFs wie ModSecurity oder Plugins wie Wordfence. Das Ergebnis sind 403 Forbidden– oder 429 Too Many Requests-Fehler beim POST. Lösung: Die n8n-Cloud-IP-Range im Hosting-Panel whitelisten oder auf Self-Hosted n8n mit eigener IP umsteigen.
Status draft ist nicht optional – wer hier publish setzt, riskiert, dass halluzinierte Inhalte oder kaputtes HTML live gehen. Jeder generierte Artikel braucht ein menschliches Review, bevor er veröffentlicht wird.
n8n Automation Workflows für Marketing-Teams
Das LLM-Duell für Content-Erstellung: Google Gemini vs. Anthropic Claude 3.5 Sonnet
Für hochskalierte Massen-Inhalte und datenintensive Recherchen ist Google Gemini Flash die wirtschaftlichere Wahl – dank niedrigem Token-Preis und riesigem Kontextfenster. Für anspruchsvolle Premium-Inhalte, die ohne aufwendiges Nach-Prompting natürlich und menschlich klingen müssen, liefert Anthropic Claude 3.5 Sonnet die überlegene Tonalität. Der Königsweg in KI-Workflows für Marketer mit n8n: beide Modelle kombinieren.
Der Kosten- und Skalierungsfaktor im Detail
Wer täglich dutzende Artikel automatisiert generiert, muss die Token-Kosten im Griff haben. Hier trennt sich die Spreu vom Weizen – und Gemini hat einen strukturellen Preisvorteil.
Kriterium
Google Gemini 3.5 Flash
Anthropic Claude 3.5 Sonnet
Preis Input-Token
0,50 $ pro 1M Token
3,00 $ pro 1M Token
Preis Output-Token
3,00 $ pro 1M Token
15,00 $ pro 1M Token
Kontextfenster
1.000.000 Token
200.000 Token
Context Caching
Ja – bis zu 90 % Ersparnis bei wiederkehrenden Prompts
Prompt Caching verfügbar, geringere Ersparnis
Stärke
Masse, Speed, Datenanalyse
Tonalität, Struktur, Premium-Content
Die Token-Rechnung in der Praxis: Angenommen, ein typischer SEO-Artikel benötigt ca. 3.000 Input-Token (System-Prompt + Konkurrenz-Markdown) und generiert ca. 2.000 Output-Token. Bei 50 Artikeln pro Tag ergibt sich:
Gemini Flash: ~0,075 $ Input + ~0,30 $ Output = ca. 0,38 $ pro Tag
Claude 3.5 Sonnet: ~0,45 $ Input + ~1,50 $ Output = ca. 1,95 $ pro Tag
Das ist Faktor 5. Auf einen Monat hochgerechnet summiert sich der Unterschied auf rund 47 $ – bei größeren Volumina oder längeren Kontexten (Konkurrenzanalysen mit komplettem Seiten-Markdown) wird die Schere noch deutlich größer.
Context Caching als Hebel: Gemini ermöglicht das dauerhafte Vorhalten von System-Prompts, Marken-Richtlinien oder SEO-Styleguides im Cache. Wer bei jedem API-Call denselben 1.500-Token-System-Prompt mitschickt, zahlt diesen nach dem ersten Caching nur noch zu einem Bruchteil. Bei Massengenerierungen mit identischem Briefing-Kontext ein echter Kostenkiller. Mehr zur Leistungsfähigkeit von Gemini im Profi-Einsatz liefert die Analyse zu Google Deep Research mit Gemini Pro.
Tonalität und Textstruktur: Mensch vs. Maschine
Kosten sind nur die halbe Wahrheit. Wer den Output direkt auf einem Corporate Blog veröffentlichen will, braucht Texte, die nicht nach Maschine klingen.
Das Problem mit Gemini: In Developer-Communities (Reddit r/LocalLLaMA, r/OpenAI) wird konsistent berichtet, dass Gemini-Modelle ohne strikte Negativ-Prompts repetitiv und roboterhaft schreiben. Typische Symptome: generische Einleitungen, identische Satzstrukturen über Absätze hinweg, übermäßiger Gebrauch von Aufzählungen statt Fließtext. Wer das in den Griff bekommen will, braucht aufwendige Prompt-Engineering-Arbeit mit expliziten Verboten und Stilanweisungen.
Die Stärke von Claude: Claude 3.5 Sonnet liefert erfahrungsgemäß abwechslungsreichere Satzstrukturen, bessere semantische Tiefe und eine natürlichere Tonalität – oft schon beim ersten Durchlauf. Für Inhalte, die ohne manuelles Redigieren veröffentlicht werden sollen, spart das erheblich Zeit im Workflow.
Hybrid-Modell als Königsweg im n8n-Workflow
Die pragmatische Lösung: Beide Modelle in einem zweistufigen n8n-Workflow kombinieren.
Stufe 1 – Gemini Flash als Recherche-Engine: Der AI Agent Node ruft Gemini 3.5 Flash auf, um SERP-Daten zu aggregieren, Konkurrenz-Markdown zu analysieren und eine strukturierte Gliederung mit Kernaussagen zu erstellen. Hier spielt Gemini seine Stärken aus: günstiger Preis, riesiges Kontextfenster für lange Konkurrenzseiten, schnelle Verarbeitung.
Stufe 2 – Claude als Texter: Ein zweiter Node übergibt die Gemini-Gliederung an Claude 3.5 Sonnet mit einem fokussierten Schreib-Prompt. Claude erhält nur die vorbereiteten Daten (deutlich weniger Token als das Roh-Markdown) und schreibt den finalen Artikel mit natürlicher Tonalität.
// n8n Code Node: Gemini-Output für Claude aufbereiten
const geminiOutput = $input.first().json;
const claudePrompt = `
Du bist Senior-Redakteur für einen Tech-Blog.
Schreibe einen SEO-optimierten Artikel basierend auf dieser Gliederung:
${geminiOutput.outline}
Fokus-Keyword: ${geminiOutput.keyword}
Tonalität: Fachlich, direkt, ohne KI-Floskeln.
Format: Valides HTML mit H2/H3-Struktur.
`;
return [{ json: { prompt: claudePrompt, keyword: geminiOutput.keyword } }];
Der wirtschaftliche Effekt: Claude bekommt nur die komprimierte Gliederung (ca. 500–800 Token statt 10.000+ Token Roh-Markdown). Das reduziert die Claude-Kosten pro Artikel drastisch, während die teure Vorarbeit beim günstigen Gemini Flash liegt.
Wichtige Einschränkung: Dieses Hybrid-Modell erhöht die Workflow-Komplexität. Zwei API-Anbindungen bedeuten zwei potenzielle Fehlerquellen, zwei Rate-Limit-Logiken und doppelten Monitoring-Aufwand. Für Teams, die gerade erst mit automatisierter Content-Erstellung starten, ist ein Single-Model-Ansatz mit Gemini Flash und gutem Prompt-Engineering oft der bessere Einstieg.
Claude 3.5 Sonnet im Detail
Die ungeschönte Realität: Technische Hürden und wie man sie löst
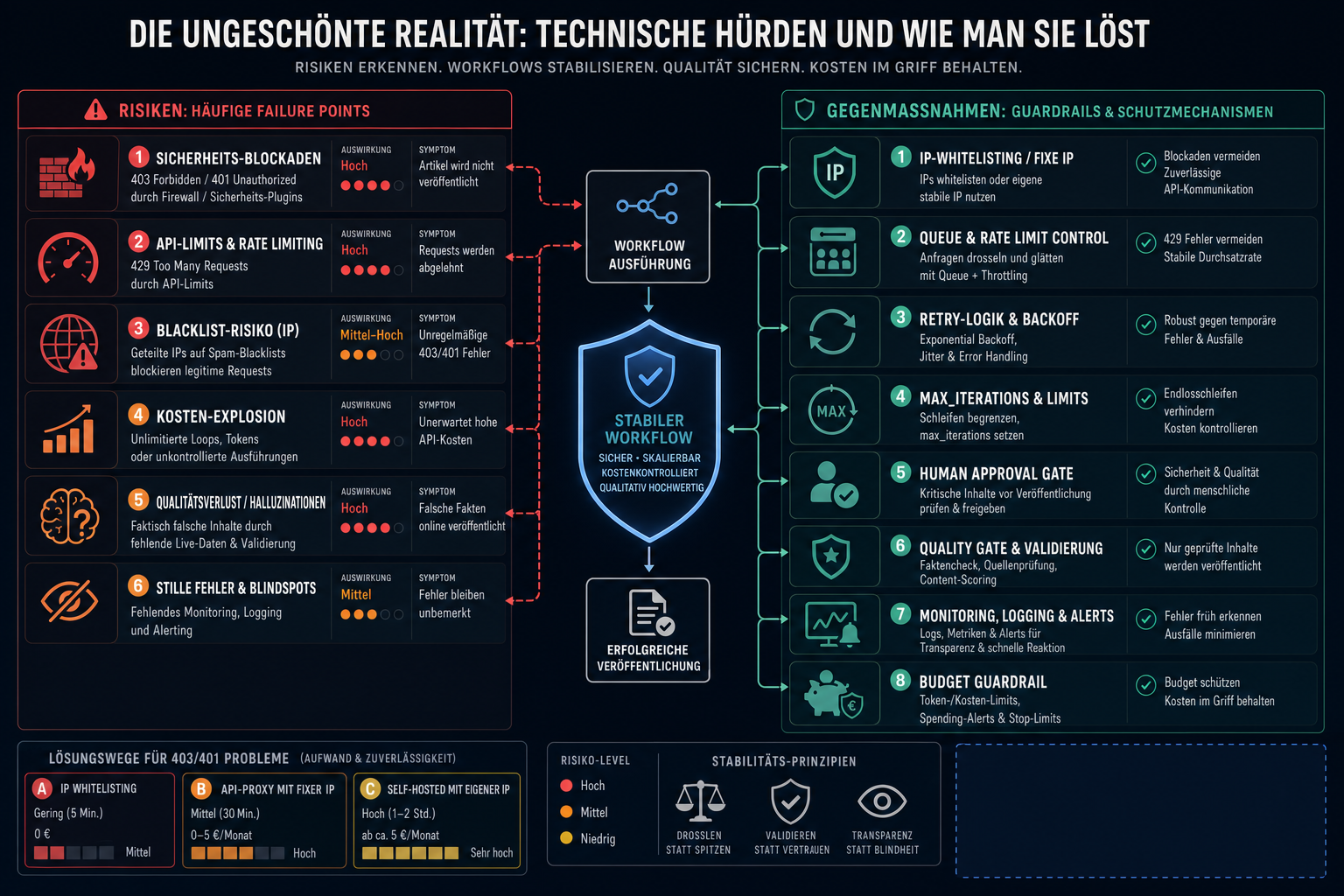
Visualisierung zum Abschnitt: Die ungeschönte Realität: Technische Hürden und wie man sie löst
Automatisierte KI-Workflows für Marketer mit n8n scheitern in der Praxis selten am Prompt-Design – sie scheitern an Firewall-Blockaden, API-Rate-Limits und LLM-Halluzinationen. Die drei häufigsten Produktiv-Probleme sind 403 Forbidden durch Sicherheits-Plugins, 429 Too Many Requests durch API-Limits und faktisch falsche Inhalte durch fehlende Live-Datenabgleiche. Hier sind die konkreten Workarounds.
Das IP-Throttling- und Firewall-Problem
Das Phänomen: Der n8n-Workflow läuft sauber durch, der WordPress-Node sendet den fertigen Artikel per POST-Request an die REST-API – und bekommt einen 403 Forbidden oder 401 Unauthorized zurück. Der Artikel landet nirgends.
Warum das passiert: Shared-Hosting-Anbieter und Sicherheits-Plugins wie Wordfence oder serverseitige Web Application Firewalls (ModSecurity) blockieren eingehende POST-Requests von IP-Adressen, die auf Spam-Blacklists stehen. Das Problem: n8n-Cloud-Instanzen teilen sich IP-Pools. Wenn andere Nutzer über dieselben IPs Spam verschickt haben, landet die gesamte IP-Range auf der Blocklist – und dein legitimer API-Call wird abgelehnt.
Drei Lösungswege nach Aufwand sortiert:
Lösung
Aufwand
Kosten
Zuverlässigkeit
n8n-Cloud-IPs in Wordfence/WAF whitelisten
Gering (5 Min.)
0 €
Mittel – IPs können sich ändern
API-Proxy mit fester IP (z. B. über Cloudflare Worker)
Mittel (30 Min.)
0–5 €/Monat
Hoch
n8n Self-Hosted auf eigenem VPS mit dedizierter IP
Hoch (1–2 Std. Setup)
Ab ca. 5 €/Monat (z. B. Hetzner)
Sehr hoch
Die Self-Hosted-Variante hat einen doppelten Vorteil: Unbegrenzte Workflow-Ausführungen bei 0 € Lizenzgebühr und eine stabile, eigene IP, die du vollständig kontrollierst. Wer im n8n-Cloud-Starter-Tarif mit 2.500 Ausführungen pro Monat arbeitet und Polling-Trigger nutzt, verbrennt sein Kontingent ohnehin schnell – ein weiterer Grund, Self-Hosting ernsthaft zu prüfen.
API-Ratenbegrenzungen (Rate Limits) abfangen
Das Problem: Das Google AI Studio Free Tier erlaubt laut Google-Dokumentation nur 2 Requests pro Minute (RPM) und 50 Requests pro Tag (RPD). Wer einen Workflow baut, der in einer Schleife mehrere Artikel oder Abschnitte generiert, reißt dieses Limit in Sekunden. Der Workflow bricht mit 429 Too Many Requests ab.
Nach diesem Code-Node folgt ein Wait-Node, der bei retry: true den Workflow für 35 Sekunden pausiert und dann den Gemini-API-Call erneut auslöst. Alternativ: Direkt auf den Pay-as-you-go-Tarif wechseln. Gemini Flash kostet dort nur 0,50 $ pro 1M Input-Token – bei einem typischen 2.000-Wort-Artikel mit Prompt liegt man unter 0,01 $ pro Generierung.
Wichtig: Auch im bezahlten Tier existieren Rate Limits, sie sind nur deutlich höher. Wait-Nodes als Sicherheitsnetz einzubauen, ist auch dort sinnvoll.
Halluzinationen und Fakten-Checks im automatisierten Workflow
Das größte Risiko automatisierter Content-Pipelines sind keine technischen Fehler, sondern inhaltliche. Gemini-Modelle halluzinieren – sie erfinden Jahreszahlen, Preise, Produktnamen oder Statistiken, die plausibel klingen, aber falsch sind. In Reddit-Communities (r/LocalLLaMA) wird Gemini eine spürbar höhere Halluzinationsrate bei Live-Datenanalysen zugeschrieben als etwa Claude.
Der Workaround: Ein paralleler Fact-Check-Branch im Workflow.
Statt den generierten Text blind an WordPress zu senden, baust du nach dem Gemini-Node einen parallelen HTTP-Request-Node ein, der kritische Behauptungen gegen eine Live-Quelle prüft:
Preise und Produktnamen: HTTP-Request an die Google Search API oder Perplexity API mit der Frage „Aktueller Preis von [Produkt X)“
Jahreszahlen und Fakten: Abgleich über einen zweiten, kürzeren Gemini-Call mit dem expliziten Prompt: _„Prüfe folgende Aussagen auf faktische Korrektheit. Antworte nur mit TRUE oder FALSE pro Aussage.“_
Ergebnis-Merge: Ein nachgeschalteter Code-Node vergleicht die Fact-Check-Ergebnisse mit dem Originaltext und flaggt Abweichungen
Realistisch betrachtet: Ein vollautomatischer Faktencheck fängt grobe Fehler ab, ersetzt aber kein menschliches Review. Deshalb bleibt die wichtigste Sicherheitsmaßnahme, den WordPress-Post-Status auf draft zu setzen – nie auf publish. Jeder Artikel durchläuft eine manuelle Freigabe.
Checkliste: Workflow-Härtung vor dem Go-Live
[ ] WordPress-Node auf Status draft konfiguriert
[ ] Wait-Node nach jedem Gemini-API-Call (mindestens 30 Sek. im Free Tier)
[ ] Error-Trigger-Workflow für 429– und 403-Fehler eingerichtet
[ ] n8n-Cloud-IPs in Wordfence oder WAF gewhitelistet – oder Self-Hosted mit fester IP
[ ] HTML-Sanitization-Node nach dem LLM-Output (entfernt \\\`html-Wrapper)
[ ] Mindestens ein Fact-Check-Node für Preise, Zahlen und Eigennamen
n8n Self-Hosting Anleitung
FAQ: Häufige Fragen zu KI-Workflows für Marketer mit n8n
Die wichtigsten Praxisfragen rund um n8n-Automatisierung, Google Gemini, WordPress-Anbindung und SEO-konforme Content-Erstellung – direkt beantwortet. Jede Antwort basiert auf realen technischen Limits, Community-Erfahrungen und dokumentierten API-Spezifikationen.
Kann ich n8n komplett kostenlos für meine Marketing-Automatisierung nutzen?
Ja, mit Einschränkungen. Die n8n Community Edition (CE) ist quelloffen und kann kostenlos auf einem eigenen Server installiert werden. Die reinen Hosting-Kosten liegen bei etwa 5 $ pro Monat für einen VPS (z. B. Hetzner CX22 oder PikaPods). Dabei gibt es keine Begrenzung der Workflow-Ausführungen – ein entscheidender Vorteil gegenüber der n8n Cloud, wo der Starter-Tarif bei 2.500 Ausführungen pro Monat deckelt.
Was die Self-Hosted-Variante nicht bietet: native Team-Kollaboration (keine Workflow-Freigabe zwischen Usern), kein SSO/LDAP und keine globalen Variablen auf UI-Ebene. Für Solo-Marketer oder kleine Teams ist das kein Problem. Sobald mehrere Personen gleichzeitig an Workflows arbeiten müssen, wird die Cloud-Variante oder ein Enterprise-Self-Hosting relevant.
Warum blockiert WordPress die REST-API-Verbindung von n8n?
Das häufigste Problem sind Sicherheitsplugins und serverseitige Firewalls. Plugins wie Wordfence oder iThemes Security blockieren automatisierte POST-Anfragen standardmäßig. Zusätzlich setzen viele Shared-Hosting-Anbieter (Hostinger, GoDaddy) Web Application Firewalls wie ModSecurity ein, die n8n-Cloud-Requests mit 403 Forbidden oder 429 Too Many Requests abweisen.
Erschwerender Faktor: Da sich viele n8n-Cloud-Instanzen dieselbe IP-Adresse teilen, landen diese IPs häufiger auf Spam-Listen. Die Lösung:
n8n-IP-Adressen explizit in der Firewall und im Sicherheitsplugin whitelisten
Authentifizierung über Application Passwords (Standard seit WordPress 5.6) via HTTPS Basic Auth konfigurieren
Bei persistenten Problemen: Self-Hosted n8n mit fester, eigener IP nutzen
Ist automatisch generierter Content aus n8n-Workflows schädlich für Google-Rankings?
Nein – solange der Inhalt echten Mehrwert bietet. Google straft KI-generierte Inhalte nicht pauschal ab. Die Spam-Policy richtet sich gegen minderwertigen, massenhaft produzierten Content ohne Information Gain. Ein n8n-Workflow, der vor der Texterstellung SERP-Daten scrapt, Konkurrenzinhalte analysiert und diese Daten als Kontext an Google Gemini übergibt, produziert qualitativ bessere Ergebnisse als ein simpler Standard-Prompt.
Entscheidend ist die Pipeline-Architektur:
Workflows, die nur „Schreibe einen Artikel über X“ an ein LLM senden, erzeugen generischen Output
Workflows mit vorgeschaltetem SERP-Scraping, Konkurrenz-Analyse und strukturiertem Prompt-Engineering liefern differenzierten Content
Der Status draft als Standard-Ausgabe im WordPress-Node ermöglicht ein manuelles Review vor der Veröffentlichung – das ist keine optionale Empfehlung, sondern Pflicht für SEO-relevante Inhalte
Wie sicher sind meine API-Keys und Kundendaten in n8n?
Die Sicherheit hängt vom Hosting-Modell ab. In der n8n Cloud werden Credentials verschlüsselt gespeichert. Wer absolute Datenhoheit benötigt – etwa wegen DSGVO-Anforderungen im Umgang mit Kundendaten oder personenbezogenen Informationen – sollte die Self-Hosted-Variante auf einem europäischen Server betreiben.
Kriterium
n8n Cloud
n8n Self-Hosted
Datenstandort
Vom Anbieter verwaltet
Frei wählbar (z. B. EU-Rechenzentrum)
Credential-Verschlüsselung
Ja, serverseitig
Ja, konfigurierbar via Encryption Key
DSGVO-Kontrolle
Eingeschränkt (Auftragsverarbeitung)
Volle Kontrolle
API-Key-Verwaltung
Über n8n-UI
Über n8n-UI + Umgebungsvariablen
Kann ich statt Google Gemini auch OpenAI GPT-4o oder Claude einbinden?
Ja, n8n bietet native Nodes für OpenAI, Anthropic und weitere LLM-Anbieter. Die Workflow-Struktur bleibt identisch – es müssen lediglich die API-Credentials und der Node-Typ ausgetauscht werden. Die Wahl des Modells hat allerdings direkte Auswirkungen auf Kosten und Textqualität:
Gemini Flash ist der Preis-Leistungs-Sieger für Massengenerierung (0,50 $ pro 1M Input-Token)
Claude 3.5 Sonnet schreibt laut Community-Feedback natürlicher und benötigt weniger Prompt-Guardrails für hochwertige Corporate-Texte
GPT-4o liegt preislich und qualitativ dazwischen und bietet das breiteste Ökosystem an Drittanbieter-Integrationen
Der Wechsel zwischen Modellen ist im n8n-Editor eine Sache von Minuten – ein klarer Vorteil gegenüber hart-codierten API-Integrationen.
Wie automatisiere ich die Bildrecherche im Workflow?
Über einen HTTP Request Node, der die Pexels- oder Unsplash-API abfragt. Der Workflow sucht anhand des Fokus-Keywords nach lizenzfreien Bildern, extrahiert die Bild-URL aus der JSON-Antwort und lädt das Bild über die WordPress REST-API in die Mediathek hoch.
Der entscheidende Schritt danach: Das Bild wird nicht nur hochgeladen, sondern über einen zweiten WordPress-Node als Featured Image dem Beitrag zugewiesen – inklusive automatisch generiertem Alt-Tag auf Basis des Fokus-Keywords. Das spart pro Artikel 5–10 Minuten manuelle Arbeit in der Mediathek.
n8n Workflow-Automatisierung für Marketing-Teams
Fazit
KI-Workflows für Marketer mit n8n revolutionieren die automatisierte Content-Erstellung, indem sie starre, lineare Automatisierungen durch intelligente, code-gestützte Multi-Agenten-Systeme ersetzen. Die Kombination aus flexibler API-Orchestrierung und unbegrenzten Ausführungen via Self-Hosting macht die Plattform zur technisch überlegenen Alternative gegenüber klassischen SaaS-Tools. Wer die Hürden der WordPress-REST-API und des Prompt-Engineerings meistert, baut sich hiermit eine hocheffiziente, fast kostenlose Marketing-Maschine.
Key Takeaways zur Workflow-Automatisierung
KI-Workflows für Marketer mit n8n minimieren die Betriebskosten: Im Gegensatz zu Make.com rechnet n8n pro erfolgreichem Durchlauf (Execution) ab. Ein komplexer Loop über 50 Artikel kostet hier exakt eine statt über 200 gebührenpflichtige Operations.
Self-Hosting bietet maximale Datenkontrolle: Die quelloffene Community Edition läuft stabil auf einem 5-Euro-VPS (z. B. bei Hetzner), eliminiert jegliche künstliche Begrenzung der Ausführungen und garantiert volle DSGVO-Konformität bei der Verarbeitung sensibler Kundendaten.
Google Gemini Flash dominiert bei der Skalierung: Mit einem unschlagbaren Pricing von nur 0,50 $ pro 1 Million Input-Token und einem gigantischen Kontextfenster von 1.000.000 Token ist das Google-Modell der absolute Preissieger für die datenintensive Konkurrenzanalyse.
Claude 3.5 Sonnet sichert die Premium-Tonalität: Für den finalen, natürlich wirkenden Text-Output empfiehlt sich Anthropic Claude im Hybrid-Modell, da Gemini-Modelle ohne massives Prompting oft robotisch und repetitiv schreiben.
Menschliche Qualitätskontrolle bleibt unverzichtbar: Um SEO-Abstrafungen durch Halluzinationen zu verhindern, ist der WordPress-Post-Status draft (Entwurf) im API-Node zwingende Pflicht – ein automatischer Veröffentlichungs-Autopilot ist grob fahrlässig.
REST-API-Blockaden erfordern technisches Know-how: Typische WordPress-Verbindungsfehler (wie 403 Forbidden) durch Sicherheits-Plugins lassen sich nur durch Whitelisting der n8n-Cloud-IPs oder eine eigene, dedizierte VPS-Server-IP umgehen.
Für wen lohnt sich das? (Und für wen nicht?)
Kauf oder hoste n8n, wenn du eine SEO-Agentur, ein datengetriebenes Marketing-Team oder ein technisch versierter Solo-Marketer bist. Wenn du regelmäßig hunderte Blogbeiträge, Keyword-Recherchen oder Social-Media-Kampagnen orchestrieren willst und keine Angst vor JSON-Objekten, REST-Schnittstellen und ein paar Zeilen JavaScript im Code-Node hast, ist n8n der absolute Jackpot.
Lass die Finger davon, wenn du eine reine No-Code-Lösung suchst, die sich per Klick-and-Drop in fünf Minuten von selbst einrichtet. Wenn Begriffe wie „API-Rate-Limits“, „Hosting-WAF“ oder „Callback-URL“ bei dir Schweißausbrüche verursachen und du keinen Entwickler an der Hand hast, wirst du an den Detail-Tücken der n8n-Integration verzweifeln. In diesem Fall fährst du mit einfacheren (aber deutlich teureren) Standard-Tools im SaaS-Abo stressfreier.
Nächster Schritt: Wie du jetzt startest
Der logische nächste Schritt ist nicht der teure Einstieg in die n8n Cloud, sondern das Aufsetzen einer kostenlosen Self-Hosted-Instanz. Teste den im Artikel beschriebenen „Keywordo-kun“-Workflow zunächst mit einer Handvoll Keywords im Free-Tier von Google AI Studio, um ein Gefühl für das Zusammenspiel aus Prompt, JSON-Bereinigung und WordPress-Import zu bekommen. Sobald die Pipeline fehlerfrei läuft und die ersten Entwürfe automatisiert im CMS landen, kannst du überlegen, teurere APIs wie Claude 3.5 Sonnet für das finale Copywriting via Hybrid-Modell hinzuzuschalten.
KI-Workflows für Marketer mit n8n bleiben die ultimative Geheimwaffe für skalierbares Content-Engineering, weil sie maximale Flexibilität mit unschlagbarer Kosteneffizienz vereinen, was es für zukunftsorientierte Marketing-Teams unverzichtbar macht, sich jetzt mit dieser Open-Source-Alternative vertraut zu machen.
Florian Schröder ist Experte im Online-Marketing mit Schwerpunkt PPC (Pay-Per-Click) Kampagnen. Die revolutionären Möglichkeiten der KI erkennt er nicht nur, sondern hat sie bereits fest in seine tägliche Arbeit integriert, um innovative und effektive Marketingstrategien zu entwickeln.
Er ist überzeugt davon, dass die Zukunft des Marketings untrennbar mit der Weiterentwicklung und Nutzung von künstlicher Intelligenz verbunden ist und setzt sich dafür ein, stets am Puls dieser technologischen Entwicklungen zu bleiben.
Wir verwenden Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wir tun dies, um das Surferlebnis zu verbessern und um personalisierte Werbung anzuzeigen. Wenn Sie diesen Technologien zustimmen, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn Sie Ihre Zustimmung nicht erteilen oder zurückziehen, können bestimmte Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.