Der n8n ai agent bezeichnet seit dem Release des @n8n/agents TypeScript SDKs im März 2026 einen autonomen Software-Akteur, der visuelle Workflows über das Vercel AI SDK (ai v6) mit Code-First-Logik verbindet und über 400 native API-Knoten ansteuert.
Kollaborative Multi-Agenten-Systeme bezeichnen strukturierte Supervisor-Worker-Architekturen zur Aufteilung komplexer Prozesse, welche laut Anthropic-Benchmarks die Genauigkeit gegenüber Einzel-Agenten um 90,2 % steigern – bei einem gleichzeitig 15-fach höheren Token-Verbrauch.
Architektur zur Latenz-Reduzierung: Binden Sie dedizierte Vektordatenbanken wie Qdrant, Pinecone oder pgvector nativ in n8n-RAG-Workflows ein – dies senkt die Inferenz-Latenz um bis zu 30 % im Vergleich zu Legacy-JSON-Schnittstellen.
Plattform-Kostenkontrolle: Nutzen Sie das vorteilhafte Flat-per-Execution-Abrechnungsmodell von n8n (welches bereits ab 2.500 Executions/Monat im Starter-Tarif greift), sichern Sie Schleifen im Canvas jedoch zwingend mit einem manuellen max_iterations-Counter gegen unkontrollierte LLM-API-Kosten ab.
Enterprise-Validierung: Setzen Sie auf DSGVO-konformes Self-Hosting für maximale Datensouveränität – gestützt durch n8ns native Integration in das SAP Joule Studio (1,3-%-Beteiligung) und eine n8n-Marktbewertung von 5,2 Milliarden US-Dollar im Mai 2026.
n8n ai agent: Die wichtigsten Infos
Die Automatisierungsplattform n8n hat sich durch das neue @n8n/agents SDK und die tiefe SAP-Integration zu einer führenden Orchestrierungsschicht für Enterprise-KI entwickelt.
Statt starrer, linearer Pipelines ermöglicht das Tool nun den Aufbau autonomer Multi-Agenten-Systeme, bei denen ein zentraler Orchestrator-Agent spezialisierte Sub-Agenten steuert.
Dieser hybride Ansatz verbindet die Flexibilität von TypeScript-Code mit über 400 visuell konfigurierbaren API-Schnittstellen auf einer grafischen Oberfläche.
Für dein Unternehmen bedeutet das bis zu 90 Prozent präzisere Arbeitsergebnisse bei komplexen Prozessen, erfordert aber wegen eines 15-fach höheren Token-Verbrauchs ein aktives Kostenmanagement.
Da n8n nach einer Flatrate pro Workflow-Ausführung abrechnet und komplett DSGVO-konform selbst gehostet werden kann, sparst du im Vergleich zu Zapier massive Plattformgebühren und behältst die volle Datensouveränität.
Baue für den schnellen Einstieg eine hierarchische Orchestrator-Worker-Architektur auf, bei der ein Premium-Modell wie Claude 3.5 Sonnet die Aufgaben an kostengünstigere Helfer-Modelle wie GPT-4o-mini delegiert.
Definiere im ersten Schritt klare JSON-Schnittstellen für deine Sub-Agenten und beschränke deren Werkzeuge, um Fehlentscheidungen der KI zu minimieren.
Integriere zudem zwingend harte Schleifen-Limits in deinen n8n-Workflow, um unkontrollierte API-Kosten durch fehlerhafte Agenten-Schleifen von Anfang an auszuschließen.
n8n definiert mit dem neuen @n8n/agents TypeScript SDK die Orchestrierung von KI neu und etabliert den n8n ai agent als code-first gesteuerte Enterprise-Lösung für autonome Multi-Agenten-Systeme. Dieser Schritt ist wegweisend, da Multi-Agenten-Systeme die Genauigkeit komplexer Aufgaben laut Benchmarks um 90,2 Prozent steigern, allerdings um den Preis eines signifikant höheren Token-Verbrauchs. Diese Analyse beleuchtet das 2026-Framework-Update, die kritischen Einwände der Developer-Community sowie praxiserprobte hierarchische Workflows.
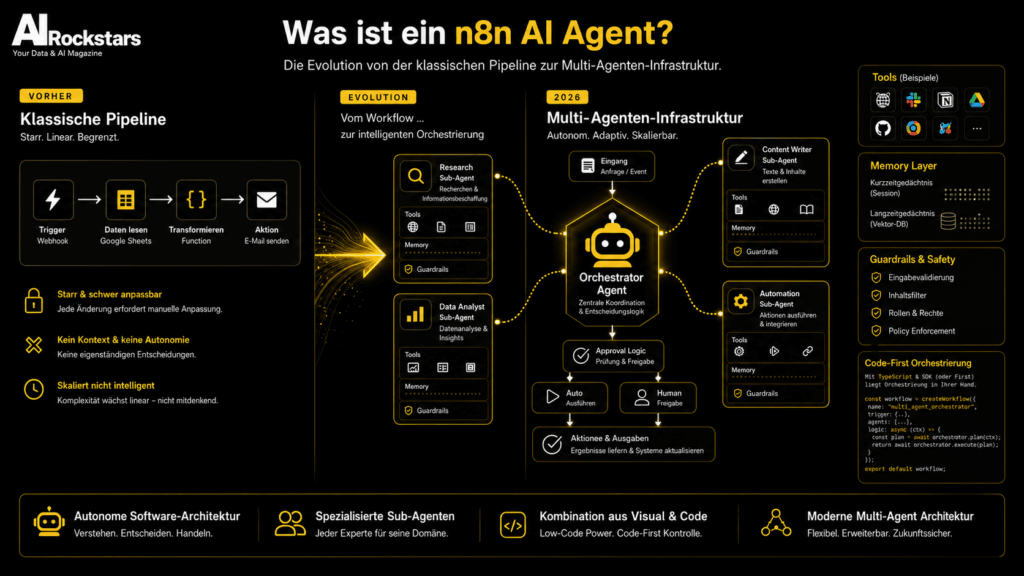
Was ist ein n8n ai agent? Die Evolution von der klassischen Pipeline zur Multi-Agenten-Infrastruktur
Was ist ein n8n ai agent? Die Evolution von der klassischen Pipeline zur Multi-Agenten-Infrastruktur
Visualisierung zum Abschnitt: Was ist ein n8n ai agent? Die Evolution von der klassischen Pipeline zur Multi-Agenten-Infrastruktur
Ein n8n ai agent ist 2026 kein simples No-Code-Skript mehr. Es handelt sich um einen autonomen Software-Akteur innerhalb einer Multi-Agenten-Infrastruktur, der über das native @n8n/agents TypeScript SDK deklariert wird. Statt linearer Pipelines orchestriert n8n spezialisierte Sub-Agenten mit eigenen Tools, Memory-Strukturen und Guardrails – und verbindet dabei visuelle Workflows mit Code-First-Logik.
Vom No-Code Tool zur Enterprise AI Orchestration Engine
n8n hat sich in den letzten Jahren fundamental gewandelt. Was als Open-Source-Alternative zu Zapier begann – ein visuelles Automatisierungstool für Webhooks und API-Calls – ist 2026 eine vollwertige KI-Orchestrierungsschicht für Großunternehmen.
Der entscheidende Wendepunkt: Im März 2026 veröffentlichte n8n das @n8n/agents TypeScript SDK, aufbauend auf dem Vercel AI SDK (ai v6). Damit können Entwickler Agenten, Tools und Sicherheitsleitplanken direkt im Code instanziieren – ohne auf die visuelle Canvas-Oberfläche beschränkt zu sein.
Die strategische Validierung folgte zwei Monate später: SAP integrierte n8n nativ als Orchestrierungsschicht in sein Joule Studio und erwarb eine 1,3-%-Beteiligung. n8ns Bewertung stieg auf 5,2 Milliarden US-Dollar. Das ist kein Nischen-Tool mehr. Das ist Enterprise-Infrastruktur.
Was bedeutet das konkret? Unternehmen, die SAP-Systeme betreiben, können n8n-Agenten direkt innerhalb der SAP-Plattform als autonome Prozessakteure einsetzen – DSGVO-konform, self-hosted, mit voller Datensouveränität.
Der Paradigmenwechsel 2026: Warum RAG allein nicht mehr reicht
RAG (Retrieval-Augmented Generation) war 2024 noch der heilige Gral der KI-Automatisierung. 2026 ist es Commodity-Infrastruktur. Jede halbwegs brauchbare Plattform bietet Vektordatenbank-Anbindungen, Chunk-Strategien und Embedding-Pipelines out of the box. Wer heute noch mit „Wir machen RAG“ wirbt, sagt im Grunde: „Wir haben eine Datenbank.“
Der echte Wettbewerbsvorteil liegt in Multi-Agenten-Systemen. Warum? Weil komplexe Geschäftsprozesse nicht durch einen einzelnen Prompt mit einer riesigen Wissensbasis gelöst werden. Sie erfordern die dynamische Aufteilung in spezialisierte Unteraufgaben:
Ein Orchestrator-Agent analysiert die Anfrage und entscheidet, welche Spezialisten gebraucht werden.
Ein Research-Worker durchsucht Vektordatenbanken und liefert kontextualisierte Ergebnisse zurück.
Ein Action-Worker führt Transaktionen aus – CRM-Updates, Slack-Nachrichten, Ticket-Erstellung.
Anthropic-Benchmarks, die n8n in internen Whitepapers zitiert, belegen: Kollaborative Multi-Agenten-Systeme (Supervisor-Worker-Setups) übertreffen Einzel-Agenten-Systeme in der Genauigkeit um 90,2 %. Der Preis dafür ist allerdings real: ein 15-fach höherer Token-Verbrauch. Wer Multi-Agenten-Architekturen produktiv betreibt, muss seine Token-Kosten aktiv managen, sonst explodiert das Budget.
Das @n8n/agents SDK: Code-First statt reines Drag-and-Drop
Das @n8n/agents SDK markiert den Bruch mit der reinen No-Code-Philosophie. Entwickler können jetzt Agenten-Netzwerke programmatisch definieren, statt sie ausschließlich auf der visuellen Canvas zusammenzuklicken.
Die zentralen Klassen im Überblick:
Klasse
Funktion
Praxisrelevanz
Agent
Definiert einen einzelnen Agenten mit Modell, System-Prompt und Tool-Zugriff
Basis-Baustein jeder Architektur
Network
Verbindet mehrere Agenten zu einem kollaborativen Netzwerk
Ermöglicht Orchestrator-Worker-Topologien
Tool
Registriert externe Funktionen (APIs, Datenbanken, Sub-Workflows) als aufrufbare Werkzeuge
Schnittstelle zwischen Agent und Außenwelt
Memory
Einheitliche Speicherstruktur für Konversationshistorie und Zwischenergebnisse
Verhindert Kontextverlust über mehrere Agenten-Interaktionen
Guardrail
Vordefinierte Sicherheitsleitplanken, die Agenten-Outputs validieren
Schutz vor Halluzinationen und unerlaubten Aktionen
Eval
Auswertungsschleifen zur Qualitätsmessung direkt im n8n-Server
Automatisierte Qualitätssicherung ohne externe Tools
Der Hybrid-Ansatz ist das eigentliche Differenzierungsmerkmal: Entwickler definieren die Agenten-Logik, Guardrails und Evaluierungen im Code. Die über 400 nativen API-Knoten – Salesforce, Jira, HubSpot, Slack – werden weiterhin visuell auf der Canvas verdrahtet. Das spart Wochen an Integrationsarbeit, die in reinen Code-Frameworks wie LangGraph manuell anfallen.
Wichtig dabei: Das SDK ersetzt die visuelle Canvas nicht. Es erweitert sie. Wer einfache RAG-Pipelines mit n8n-Templates baut, braucht kein TypeScript. Wer aber Multi-Agenten-Netzwerke mit Guardrails, zyklischen Evaluierungen und dynamischem Tool-Routing in Produktion bringen will, kommt am SDK nicht vorbei.
Der „Token-Fluch“ und die Notwendigkeit spezialisierter Sub-Agenten
Visualisierung zum Abschnitt: Der „Token-Fluch“ und die Notwendigkeit spezialisierter Sub-Agenten
Multi-Agenten-Systeme lösen das fundamentale Problem begrenzter Kontextfenster, indem sie komplexe Aufgaben auf spezialisierte Sub-Agenten verteilen. Der Preis dafür ist erheblich: Laut Anthropic-Benchmarks steigt der Token-Verbrauch um das 15-Fache gegenüber Einzel-Agenten. Wer n8n AI Agent Workflows in Produktion betreibt, muss diese Kosten-Qualitäts-Abwägung von Tag eins an einplanen.
Die physischen Grenzen der Kontextfenster
Auch 2026 bleibt das Kontextfenster die Achillesferse jedes LLM-basierten Agenten. Modelle wie Claude 3.5 Sonnet oder GPT-4o akzeptieren zwar nominell Hunderttausende Tokens als Input – aber die tatsächliche Verarbeitungsqualität bricht bei großen Kontexten ein. Der sogenannte „Lost in the Middle“-Effekt ist gut dokumentiert: Informationen, die weder am Anfang noch am Ende des Kontextfensters stehen, werden vom Modell systematisch schlechter verarbeitet.
Für Enterprise-Workflows bedeutet das konkret: Ein einzelner Agent, der gleichzeitig CRM-Daten, PDF-Berichte, E-Mail-Verläufe und Datenbank-Abfragen verarbeiten soll, verliert ab einer bestimmten Datenmenge die Fähigkeit, zuverlässig zu priorisieren. Die Ergebnisse werden inkonsistent, Halluzinationen nehmen zu.
Die Lösung ist architektonischer Natur: Statt einem Generalisten-Agenten alles aufzubürden, werden spezialisierte Sub-Agenten dynamisch erstellt und verknüpft. Jeder Sub-Agent bekommt nur den Kontext, den er für seine eng definierte Aufgabe braucht. Ein RAG-Worker durchsucht ausschließlich die Vektordatenbank. Ein Action-Worker führt ausschließlich API-Calls aus. Der Orchestrator koordiniert – ohne selbst die gesamte Datenlast tragen zu müssen.
Wer bereits mit n8n Templates für RAG-Systeme arbeitet, kennt die Grundstruktur. Der Shift zu Multi-Agenten-Systemen ist die logische Weiterentwicklung dieser Architektur.
Die Überlegenheit von Multi-Agenten-Setups ist nicht nur theoretisch plausibel, sondern durch Benchmarks belegt. Anthropic hat in internen Studien gezeigt, dass Supervisor-Worker-Architekturen bei komplexen Reasoning-Tasks eine Genauigkeit von über 90 % erreichen – deutlich mehr als vergleichbare Einzel-Agenten-Systeme.
Der Mechanismus dahinter ist nachvollziehbar:
Eng begrenzte Rollendefinitionen reduzieren Halluzinationen. Ein Agent, der nur für SQL-Abfragen zuständig ist, halluziniert seltener als ein Generalist, der zwischen zehn verschiedenen Tools wählen muss.
Spezialisierte Systemprompts pro Sub-Agent erlauben präzisere Instruktionen. Der Orchestrator gibt nicht „finde relevante Daten“ vor, sondern delegiert an einen Worker mit dem exakten Auftrag „durchsuche die Qdrant-Collection inventory_2026 nach Lagerbeständen unter Mindestmenge“.
Fehler bleiben isoliert. Wenn ein Sub-Agent scheitert, kann der Orchestrator den Fehler abfangen und einen alternativen Pfad einschlagen, ohne dass der gesamte Workflow kollabiert.
In der n8n-Praxis sieht das so aus: Der Main Agent Node nutzt ein starkes Frontier-Modell als Orchestrator. Sub-Agenten werden als separate Workflows implementiert und über das Tool-Konzept (execute_workflow) aufgerufen. Jeder Sub-Workflow ist ein eigenständiger, testbarer Baustein.
Die Kehrseite der Intelligenz: Der „Token-Fluch“
Die überlegene Qualität hat einen mathematisch klaren Preis. Laut denselben Anthropic-Benchmarks wird der Performance-Gewinn mit einem 15-fach höheren Token-Verbrauch erkauft. Token-Usage erklärt über 80 % der Leistungsunterschiede bei komplexen Reasoning-Tasks.
Metrik
Einzel-Agent
Multi-Agent (Supervisor-Worker)
Genauigkeit bei komplexem Reasoning
Baseline
~90,2 % (deutlich höher)
Token-Verbrauch (relativ)
1x
~15x
Halluzinationsrisiko
Hoch bei breitem Kontext
Niedrig durch Spezialisierung
Fehler-Isolation
Keine (Totalausfall)
Pro Sub-Agent isoliert
Für n8n-Anwender bedeutet das: Die Execution-basierte Abrechnung von n8n selbst ist nicht das Problem – ein kompletter Multi-Agent-Workflow zählt als eine einzige Execution. Die eigentliche Kostenexplosion passiert auf der LLM-API-Seite. Jeder Sub-Agent-Aufruf generiert eigene Prompt-Tokens, eigene Completion-Tokens, eigene System-Prompt-Overhead-Kosten.
Drei Hebel reduzieren den Token-Fluch in der Praxis:
Modell-Tiering: Der Orchestrator nutzt ein teures Frontier-Modell für Routing-Entscheidungen. Sub-Agenten für einfache Tasks (Datenextraktion, Formatierung) laufen auf günstigeren Modellen wie Claude Haiku oder GPT-4o-mini.
Vektordatenbank-Integration: Die Anbindung dedizierter Vektordatenbanken wie Qdrant, Pinecone oder pgvector an n8n-RAG-Pipelines reduziert die Inferenz-Latenz um bis zu 30 % gegenüber Legacy-JSON-Schnittstellen. Weniger Latenz bedeutet schnellere Durchläufe und weniger Timeout-bedingte Wiederholungen.
Strikte Guardrails und Token-Budgets: Ohne programmierte Rate-Limits können fehlerhafte Agenten in Sekundenbruchteilen Hunderte von LLM-Aufrufen generieren. Die Community auf Reddit warnt regelmäßig vor solchen „Runaway-Agenten“.
Für eine systematische Strategie gegen unkontrollierte API-Kosten lohnt sich der Blick auf unseren Deep Dive zur Token-Falle bei AI-Agenten und wie du die Kosten stoppst.
Die zentrale Erkenntnis: Multi-Agenten-Systeme sind kein Luxus, sondern eine technische Notwendigkeit für komplexe Workflows. Aber wer die Token-Kosten nicht von Anfang an architektonisch mitdenkt, baut sich ein System, das zwar brillant arbeitet – und gleichzeitig das API-Budget in Tagen aufbraucht.
Blueprint für die Praxis: Die hierarchische Orchestrator-Worker-Architektur in n8n
Das stabilste Produktionsmuster für einen n8n AI Agent mit mehreren Spezialisten ist die hierarchische Orchestrator-Worker-Architektur. Ein Main Agent mit starkem Frontier-Modell fungiert als zentrales „Brain“, das Aufgaben über Tool-Deklarationen an isolierte Sub-Workflows delegiert – etwa einen RAG-Worker für Dokumentenrecherche oder einen Action-Worker für CRM-Updates und Slack-Benachrichtigungen.
Die Rollenverteilung: Orchestrator vs. Fach-Worker
Das Prinzip ist simpel, aber wirkungsvoll: Ein Agent denkt, die anderen arbeiten. Der Orchestrator trifft Entscheidungen, die Worker führen aus. Keine Demokratie, keine Verhandlung zwischen Agenten – reine Delegation.
Der Main Agent (Orchestrator) wird im n8n AI Agent Node mit einem leistungsstarken Modell konfiguriert, beispielsweise Anthropic Claude 3.5 Sonnet. Seine einzige Aufgabe: die Benutzeranfrage analysieren, den richtigen Fach-Worker auswählen und dessen Ergebnis weiterverarbeiten. Er selbst greift nie direkt auf Datenbanken oder externe APIs zu.
Die Sub-Agenten (Fach-Worker) sind eigenständige n8n-Sub-Workflows, die über das „Execute Sub-Workflow“-Tool als Werkzeuge im Orchestrator registriert werden. Jeder Worker hat genau eine Domäne:
RAG-Worker: Durchsucht Vektordatenbanken (Qdrant, pgvector) nach relevanten Dokumenten-Chunks
Action-Worker: Führt Schreiboperationen aus – CRM-Updates, E-Mail-Versand, Slack-Nachrichten
Validation-Worker: Prüft Ergebnisse gegen definierte Regeln, bevor sie an den Nutzer gehen
Der entscheidende Vorteil dieser Trennung: Jeder Worker lässt sich isoliert testen, debuggen und austauschen, ohne den Orchestrator anzufassen. Wer den RAG-Worker aufbauen will, findet bewährte Vorlagen unter n8n Templates für RAG-Systeme.
JSON-Blueprint: Das Tool-Deklarations-Schema für den Main Agent
Damit der Orchestrator weiß, wann und wie er einen Sub-Agenten ansteuern soll, wird der Sub-Workflow als Tool mit einer klaren JSON-Schnittstellendeklaration registriert. Diese Deklaration ist das Herzstück der Architektur – sie definiert, was der Worker kann und welche Parameter er erwartet:
{
"name": "execute_research_subagent",
"description": "Delegiert komplexe Recherchen zu Dokumenten und Wissensdatenbanken an den RAG-Spezialisten.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Die spezifische, verfeinerte Suchanfrage für die Vektordatenbank."
},
"max_results": {
"type": "integer",
"default": 5,
"description": "Maximale Anzahl an relevanten Textstellen, die zurückgegeben werden sollen."
}
},
"required": ["query"]
}
}
Drei Punkte, die in der Praxis den Unterschied machen:
Die description ist Prompt Engineering. Der Orchestrator entscheidet anhand dieser Beschreibung, ob er das Tool aufruft. Vage Beschreibungen führen zu falscher Tool-Auswahl – eines der häufigsten Probleme, das die Community auf Reddit dokumentiert.
max_results begrenzt den Token-Rückfluss. Ohne dieses Limit kann ein RAG-Worker Dutzende Chunks zurückliefern, die das Kontextfenster des Orchestrators sprengen.
required erzwingt Struktur. Ohne Pflichtfelder generiert der Orchestrator gelegentlich leere Aufrufe, die den Sub-Workflow sinnlos triggern und unnötig Token-Kosten verursachen.
Schritt-für-Schritt-Workflow im n8n Canvas
So sieht der konkrete Ablauf auf dem n8n Canvas aus, wenn ein Nutzer fragt: _„Prüfe unseren aktuellen Lagerbestand laut dem neuesten PDF-Bericht und sende eine Warnung per Slack.“_
Schritt
Node im Canvas
Was passiert
Kritischer Punkt
1 – Trigger
Chat Trigger / Webhook
Benutzeranfrage wird empfangen und als Input an den Main Agent weitergeleitet
Webhook-URL absichern, um unkontrollierte Trigger zu vermeiden
2 – Analyse
AI Agent Node (Orchestrator)
Main Agent analysiert den Prompt, erkennt die RAG-Notwendigkeit und ruft execute_research_subagent auf
System-Prompt muss klare Entscheidungsregeln enthalten, wann welches Tool greift
3 – RAG-Execution
Execute Sub-Workflow (RAG-Worker)
Sub-Agent chunked die Query, holt Embeddings, durchsucht pgvector und gibt strukturierte Ergebnisse zurück
Embedding-Modell und Chunk-Strategie müssen zum Dokumententyp passen
4 – Action & Delivery
Slack Node (via Orchestrator)
Main Agent verarbeitet die RAG-Ergebnisse, formuliert die Warnung und stößt das Slack-Tool an
Guardrail einbauen: Orchestrator darf nur senden, wenn RAG-Ergebnis nicht leer ist
Wo diese Architektur an Grenzen stößt
Die hierarchische Struktur ist stabil, aber nicht universell. Drei reale Einschränkungen, die Entwickler kennen sollten:
Kein natives State-Checkpointing. Stürzt der Orchestrator nach Schritt 3 ab, gibt es keinen automatischen Rollback zum letzten konsistenten Zustand. Im Vergleich zu Code-Frameworks wie LangGraph, die Zustandsgraphen mit Checkpoints bieten, muss man in n8n manuell Error-Handling-Branches bauen.
Tool-Auswahl ist fragil. Community-Berichte auf Reddit zeigen, dass Agenten bei mehr als fünf registrierten Tools zunehmend Fehler bei der Auswahl machen. Wer viele Worker betreibt, sollte die Tool-Beschreibungen extrem präzise formulieren oder einen Routing-Layer vorschalten.
Runaway-Risiko bei Schleifen. Wenn der Orchestrator in einer Schleife den gleichen Worker wiederholt aufruft – etwa weil das RAG-Ergebnis nie „gut genug“ ist – entstehen schnell Hunderte LLM-Aufrufe innerhalb einer einzigen Execution. Ein harter max_iterations-Counter im System-Prompt ist Pflicht. Für eine tiefere Analyse der Kostenrisiken lohnt sich der Vergleich mit anderen Automatisierungsplattformen und deren Abrechnungsmodellen.
Die n8n-Realität im Härtetest: Grenzen, Risiken und die Kritik der Entwickler-Community
Der n8n AI Agent ist ein mächtiges Werkzeug, aber kein Wundermittel. Die Entwickler-Community auf Reddit (r/n8n, r/AI\_Agents) kritisiert zu Recht: Viele als „Multi-Agenten-Teams“ vermarktete Workflows sind in Wahrheit starre, lineare Pipelines. Dazu kommen reale Risiken wie unkontrollierte API-Kosten durch Endlosschleifen, fehlendes natives State-Management und offene Sicherheitsfragen beim Model Context Protocol (MCP).
„Multi-Agenten-Teams“ in n8n: Marketing-Hype vs. deterministische Realität
Die Kritik aus der Community trifft einen Nerv. Ein Reddit-User bringt es auf den Punkt:
> _„Having multiple AI nodes in your n8n workflow doesn’t magically create a coordinated AI team. It just creates a sequence or network of calls you orchestrate.“_
Das Problem ist strukturell: Wer im n8n Canvas mehrere AI Agent Nodes hintereinander schaltet, baut keine emergente Agenten-Kollaboration. Es entsteht eine deterministische Pipeline, bei der jeder Schritt fest verdrahtet ist. Der Orchestrator-Node ruft Sub-Workflows in einer vordefinierten Reihenfolge auf – das ist Automatisierung, keine Autonomie.
Besonders kritisch wird es bei der Tool-Auswahl. Wenn ein Agent entscheiden muss, ob er eine SQL-Abfrage, einen API-Call oder eine Vektordatenbank-Suche ausführt, versagt der native visuelle AI Agent Node in der Praxis häufig. Die Entscheidungslogik hängt vollständig von der Prompt-Qualität und dem verwendeten LLM ab. Bei komplexen Entscheidungsbäumen mit mehr als drei bis vier Tools sinkt die Zuverlässigkeit drastisch.
Was das konkret bedeutet: Wer produktive Multi-Agenten-Systeme in n8n betreiben will, muss die Tool-Beschreibungen extrem präzise formulieren, die Anzahl verfügbarer Tools pro Agent bewusst begrenzen und im Zweifel deterministische Routing-Nodes (IF/Switch) vorschalten, statt dem LLM die Entscheidung zu überlassen.
Die Gefahr unvorhersehbarer API-Kosten („Runaway-Agenten“)
Das Horrorszenario jedes DevOps-Teams: Ein Webhook-Trigger feuert, der Agent startet eine Schleife, die Guardrails greifen nicht – und innerhalb von Sekunden generiert das System Hunderte oder Tausende LLM-Calls. Die Token-Falle bei AI-Agenten ist real und trifft n8n-Nutzer besonders hart.
Warum gerade n8n anfällig ist:
Keine nativen visuellen Rate-Limits: n8n bietet im Canvas keinen Drag-and-Drop-Node für API-Rate-Limiting. Entwickler müssen Begrenzungen manuell per Code-Node oder über externe Proxies implementieren.
Zyklische Verbindungen ohne Abbruchbedingung: Wenn ein Agent in einer Schleife steckt und das LLM keine klare Exit-Condition erkennt, läuft der Workflow weiter – mit jedem Durchlauf fallen Token-Kosten an.
Execution-Zählung verschleiert das Problem: Eine Ausführung in n8n entspricht einem vollständigen Workflow-Run. Führt ein Agent innerhalb eines Workflows 1.000 Tool-Aufrufe aus, zählt das als eine einzige Execution. Das Billing sieht harmlos aus, die LLM-Rechnung nicht.
Praxis-Empfehlung: Jeder produktive n8n AI Agent braucht mindestens drei Sicherheitsebenen: einen maximalen Loop-Counter im Code-Node, ein Token-Budget pro Workflow-Run und ein externes Monitoring (z. B. über Grafana oder Datadog), das bei Anomalien sofort den Workflow stoppt.
Das State-Management-Defizit im Vergleich zu LangGraph
Hier liegt die größte architektonische Schwäche von n8n gegenüber Code-First-Frameworks. LangGraph bietet ein natives StateGraph-System mit integriertem Checkpointing – das bedeutet: Der exakte Zustand eines Agenten kann zu jedem Zeitpunkt gespeichert, inspiziert und bei Bedarf auf einen früheren Punkt zurückgesetzt werden.
n8n hat das nicht. Stürzt ein Node mitten in einer komplexen Multi-Agenten-Transaktion ab, lässt sich der genaue Zustand des „Agenten-Gehirns“ nur schwer rekonstruieren. Die Konversationshistorie ist zwar über den Memory-Node verfügbar, aber der interne Entscheidungszustand – welche Tools wurden bereits aufgerufen, welche Teilergebnisse liegen vor, wo genau im Reasoning-Prozess befand sich der Agent – geht verloren.
Kriterium
n8n (visuell + SDK)
LangGraph (Code-First)
Zustandsspeicherung
Konversations-Memory, kein nativer State-Snapshot
Vollständiger StateGraph mit Checkpoints
Historisches Rollback
Nicht nativ möglich
Jederzeit auf beliebigen Checkpoint
Zyklische Schleifen
Möglich, aber fehleranfällig ohne Abbruchlogik
Nativ unterstützt mit Zustandskontrolle
Crash-Recovery
Workflow-Neustart, Teilzustand verloren
Wiederaufnahme ab letztem Checkpoint
Debugging komplexer Agenten
Visuell nachvollziehbar, aber State opak
Programmatisch vollständig inspizierbar
Für einfache Orchestrierungen – Webhook rein, drei Sub-Agenten nacheinander, Ergebnis raus – ist das kein Problem. Für komplexe, zyklische Systeme mit Selbstkorrekturschleifen ist es ein echtes Hindernis.
Das Sicherheitsrisiko „Model Context Protocol“ (MCP) im Enterprise-Umfeld
MCP begeistert Entwickler, weil es Agenten standardisierten Zugriff auf externe Systeme gibt. IT-Sicherheitsbeauftragte sehen das anders. Das Kernproblem: Ein LLM erhält über MCP direkten Systemzugriff – auf Datenbanken, APIs, interne Tools. Wenn der Agent halluziniert oder durch Prompt Injection manipuliert wird, agiert er mit realen Berechtigungen.
Die konkreten Enterprise-Risiken:
Schatten-APIs: MCP-Server können ohne zentrale IT-Freigabe aufgesetzt werden. Teams deployen eigene MCP-Endpunkte, die keiner Sicherheitsprüfung unterliegen.
Datenintegrität: Wenn ein Agent über MCP schreibende Zugriffe auf ein CRM oder ERP hat, kann eine fehlerhafte Tool-Auswahl reale Geschäftsdaten korrumpieren.
Validierungslücken: Die Eingaben, die ein LLM an einen MCP-Server sendet, werden oft nicht ausreichend validiert. SQL-Injection-ähnliche Angriffsvektoren sind denkbar.
Wer MCP produktiv einsetzen will, sollte die Chancen und Risiken von MCP Apps für AI-Agenten genau kennen. Ohne dedizierte Berechtigungsschichten, Input-Validierung und Audit-Logging ist MCP im Enterprise-Umfeld ein offenes Scheunentor.
n8n vs. LangGraph vs. Zapier vs. OpenAI: Der ultimative Systemvergleich
Die Wahl der richtigen Agenten-Plattform hängt 2026 von drei Faktoren ab: Datensouveränität, Kostenstruktur bei Schleifen und die Balance zwischen visueller Nachvollziehbarkeit und Code-Tiefe. n8n besetzt mit seinem Hybrid-Ansatz aus visuellem Builder und dem @n8n/agents SDK die goldene Mitte – ist aber nicht für jeden Use Case die beste Wahl.
Feature- und Architektur-Vergleich
Bevor Pricing-Tabellen die Entscheidung dominieren, lohnt sich ein Blick auf die fundamentalen Architektur-Unterschiede. Denn die Plattformwahl bestimmt nicht nur die Kosten, sondern auch die Komplexität der Agenten, die überhaupt gebaut werden können.
Kriterium
n8n (mit @n8n/agents SDK)
LangGraph (LangChain)
Zapier / Make.com
OpenAI Agent Builder
Paradigma
Hybrid (Visuell + Code-First SDK)
Pure Code (Python / TypeScript)
No-Code (starr, linear)
Closed Ecosystem (No-Code Config)
Schleifen & State-Handling
Gut über Sub-Workflows & SDK, visuell bei Tiefe unübersichtlich
Sehr schlecht (Schleifen extrem teuer und unzuverlässig)
Black Box (vollständig von OpenAI gesteuert)
Kostenstruktur
Flat pro Execution (interne Nodes unbegrenzt)
Hosting + reine LLM-Token-Kosten
Abrechnung pro Einzelschritt/Task
Token-Kosten + API-Plattformaufschlag
Hosting & Datensouveränität
Hervorragend (Self-Hosted Community Edition, DSGVO-konform)
Eigenes Cloud- oder On-Prem-Hosting nötig
Nur SaaS (Datenfluss über US-Server)
Nur SaaS (vollständige Abhängigkeit)
Native Integrationen
400+ API-Knoten out-of-the-box
Manuelle Programmierung oder LangChain-Tools
Riesiges Ökosystem, aber teuer bei Volumen
Sehr eingeschränkt (nur eigene Custom Actions)
Fehlerbehandlung bei Agenten
Visuelles Error-Handling, aber kein natives Checkpoint-Rollback
Natives Checkpointing mit historischem Rollback
Einfache Retry-Logik
Keine manuelle Kontrolle
Eine detaillierte Analyse der klassischen Automatisierungswelt liefert unser Vergleich der Automatisierungstools n8n vs. Zapier vs. Make.
Kostenanalyse: Warum das Flat-per-Execution-Modell den Unterschied macht
Das Abrechnungsmodell ist der entscheidende Hebel bei AI-Agenten-Workflows – und hier trennt sich n8n radikal von Zapier und Make.
Das Prinzip: Eine Execution in n8n entspricht einem vollständigen Workflow-Run. Führt ein n8n AI Agent innerhalb eines Workflows 1.000 Tool-Aufrufe oder Schleifen aus – etwa beim sequenziellen Auswerten eines E-Mail-Postfachs –, zählt das technisch als nur 1 Execution. Die internen Nodes sind unbegrenzt.
Bei Zapier oder Make hingegen wird jeder einzelne Schritt als separater Task abgerechnet. Ein Agent, der 50 E-Mails prüft, jeweils eine Klassifikation durchführt und bei 10 davon eine Aktion auslöst, verbraucht dort schnell 150+ Tasks – in n8n bleibt es bei einer einzigen Execution.
n8n-Tarif
Executions/Monat
Besonderheit
Starter
2.500
5 gleichzeitig aktive Workflows (Concurrency-Limit)
Pro
10.000
Höhere Concurrency
Business
40.000
Zusatzpakete: 300.000 Executions für €4.000
Enterprise
Unbegrenzt
Custom SLA & Dedicated Support
Die TCO-Falle bei Zapier/Make: Komplexe AI-Agenten mit Schleifen, Bedingungen und mehreren Tool-Aufrufen können dort innerhalb weniger Tage das monatliche Task-Budget sprengen. Wer Multi-Agenten-Systeme mit Orchestrator-Worker-Patterns betreibt, zahlt bei Zapier ein Vielfaches – nicht wegen der Logik, sondern wegen der Abrechnungsarchitektur.
Wichtig: Das Flat-per-Execution-Modell deckt nur die n8n-Plattformkosten ab. Die LLM-Token-Kosten (OpenAI, Anthropic, etc.) fallen zusätzlich an und können bei Multi-Agenten-Systemen erheblich sein. Laut Benchmarks verbrauchen kollaborative Multi-Agenten-Setups bis zu 15-mal mehr Token als Einzel-Agenten. Wer das nicht im Blick hat, tauscht die Zapier-Falle gegen die Token-Falle bei AI-Agenten.
Die strategische Entscheidung: Wann welche Plattform?
Statt einer pauschalen Empfehlung hier die konkreten Entscheidungskriterien:
n8n wählen, wenn:
Datensouveränität und Self-Hosting auf europäischen Servern nicht verhandelbar sind
Das Team hunderte API-Integrationen (Salesforce, HubSpot, Jira, Slack) braucht, ohne jede einzeln in Python zu programmieren
Workflows visuell nachvollziehbar und für nicht-technische Stakeholder transparent sein müssen
Human-in-the-Loop-Freigaben Teil des Prozesses sind
LangGraph wählen, wenn:
Hochkomplexe, zyklische Selbstkorrekturschleifen mit tiefem State Management gebraucht werden
Das Team erfahrene Python-Entwickler hat, die Zustandsgraphen mit Checkpointing und historischem Rollback benötigen
Forschungs-Agenten gebaut werden, deren Verhalten unvorhersehbar und emergent sein darf
Zapier/Make wählen, wenn:
Einfache, lineare Wenn-Dann-Automatisierungen ohne nennenswerte KI-Logik reichen
Kein Entwickler im Team ist und die Workflows unter 5 Schritte bleiben
Das Volumen niedrig genug ist, dass die Task-basierte Abrechnung nicht schmerzt
OpenAI Agent Builder meiden, wenn:
Vendor-Lock-in ein Risiko darstellt oder regulatorische Anforderungen an Datenhaltung bestehen
Ein ehrlicher Punkt zum Schluss der Einordnung: Die Community auf Reddit (r/n8n) kritisiert zurecht, dass mehrere AI-Nodes in einem n8n-Workflow noch kein echtes Multi-Agenten-System ergeben. Wer dynamische, emergente Agenten-Kollaboration braucht, muss entweder das @n8n/agents SDK nutzen oder zu LangGraph greifen. Der visuelle Builder allein liefert deterministische Pipelines – keine autonomen Agenten-Teams.
FAQ – Häufig gestellte Fragen zu n8n AI Agents
Die wichtigsten Fragen rund um n8n AI Agents betreffen Kosten, Architektur-Unterschiede, Kostenkontrolle, DSGVO-konformes Hosting, den Vergleich mit Code-Frameworks wie LangGraph und die Wahl des richtigen LLM-Modells als Orchestrator. Hier die präzisen Antworten auf Basis der aktuellen 2026er-Spezifikationen.
Was kostet die Ausführung von AI-Agenten-Workflows in n8n?
Das Preismodell von n8n basiert auf Workflow-Ausführungen (Executions), nicht auf einzelnen Node-Aufrufen oder Tool-Calls innerhalb eines Workflows. Das ist ein entscheidender Unterschied für AI-Agenten-Szenarien.
Tarif
Executions / Monat
Zusatzpakete
Starter
2.500
–
Pro
10.000
–
Business
40.000
€4.000 pro 300.000 Executions
Enterprise
Unbegrenzt
Individuell
Der Clou: Ein n8n AI Agent kann innerhalb eines einzigen Workflow-Runs hunderte Tool-Aufrufe, LLM-Abfragen oder Schleifen ausführen – das zählt technisch als nur eine Execution. Das limitierende Element ist die Concurrency, also die Anzahl gleichzeitig aktiver Workflows (im Starter-Tarif z. B. auf 5 begrenzt). Wer viele parallele Agenten-Sessions braucht, stößt hier zuerst an Grenzen – nicht beim Execution-Budget.
Was ist der Unterschied zwischen einem klassischen n8n Workflow und einem n8n AI Agent?
Ein klassischer n8n-Workflow ist deterministisch: Daten fließen starr von Node A nach B nach C. Die Reihenfolge steht fest, bevor der Workflow startet.
Ein n8n AI Agent nutzt ein LLM als zentrales Entscheidungsorgan. Der Agent analysiert den Benutzer-Prompt und entscheidet dynamisch, welche der ihm zugewiesenen Tools oder Sub-Workflows er in welcher Reihenfolge aufruft. Das Ergebnis: Derselbe Agent kann bei unterschiedlichen Eingaben völlig verschiedene Pfade durch die verfügbaren Werkzeuge nehmen.
Wichtig dabei: Mehrere AI-Nodes in einem Workflow machen noch kein koordiniertes Agenten-Team. Wie die Community auf Reddit zurecht kritisiert, bleibt es ohne echte Orchestrierungslogik eine Sequenz von LLM-Calls – kein autonomes Multi-Agenten-System.
Wie schütze ich mich vor explodierenden API-Kosten bei autonomen n8n Agenten?
Unkontrollierte „Runaway-Schleifen“ sind das größte finanzielle Risiko beim Betrieb von AI Agents. Drei konkrete Maßnahmen helfen:
Max-Iteration-Limits direkt im AI Agent Node konfigurieren – das begrenzt die Anzahl der Tool-Aufrufe pro Session hart.
Das @n8n/agents SDK nutzen, um programmatische Guardrails zu definieren, die den maximalen Token-Verbrauch pro Session deckeln.
Webhooks über Queue-Systeme entkoppeln – ohne Drosselung kann eine Webhook-Flut dutzende simultane Agenten-Sessions spawnen, die jeweils hunderte LLM-Calls auslösen.
Detaillierte Strategien zur Vermeidung der Token-Falle bei AI Agenten sind gerade bei Multi-Agent-Setups geschäftskritisch, da der Token-Verbrauch laut Benchmarks bis zu 15-fach höher ausfallen kann als bei Einzel-Agenten.
Kann ich n8n AI Agents komplett on-premise und DSGVO-konform hosten?
Ja. n8n bietet eine voll funktionsfähige selbst-hostbare Community- und Enterprise-Edition. In Kombination mit lokal gehosteten LLMs (z. B. via Ollama oder vLLM) und lokalen Vektordatenbanken (Qdrant, pgvector) lässt sich eine Architektur aufbauen, bei der keinerlei Daten die eigene Infrastruktur verlassen. Das ist ein massiver Vorteil gegenüber reinen SaaS-Plattformen wie Zapier oder dem OpenAI Agent Builder, die Daten zwingend über externe Server routen. Für den Vergleich zwischen n8n, Zapier und Make ist Datensouveränität oft das entscheidende Kriterium.
Wie schneidet der n8n AI Agent im Vergleich zu LangGraph ab?
Für Standard-Unternehmensprozesse mit menschlichen Freigabeschritten ist n8n durch die visuelle Nachvollziehbarkeit deutlich schneller zu implementieren. LangGraph bleibt die bessere Wahl für hochgradig experimentelle Agenten-Architekturen mit tiefen zyklischen Selbstkorrekturschleifen und nativem Checkpointing.
Welche LLM-Modelle eignen sich am besten als Orchestrator in n8n?
Als zentraler Orchestrator (Main Agent) sollten ausschließlich Frontier-Modelle mit starken Reasoning- und Tool-Calling-Fähigkeiten eingesetzt werden. Bewährt haben sich Anthropic Claude 3.5 Sonnet und OpenAI GPT-4o. Für lokal gehostete Enterprise-Szenarien bietet sich Llama 3.3 70B an.
Für spezialisierte Sub-Agenten (Worker), die nur klar definierte Einzelaufgaben ausführen, reichen kleinere, kostengünstigere Modelle wie GPT-4o-mini oder Llama 3B. Diese Aufteilung optimiert den Token-Verbrauch erheblich – ein kritischer Faktor, da Multi-Agenten-Systeme laut Benchmarks den Token-Bedarf um ein Vielfaches steigern. Wer RAG-Systeme in n8n als Sub-Agent-Worker einsetzt, profitiert zusätzlich von reduzierten Inferenz-Latenzen durch dedizierte Vektordatenbanken.
Fazit
Der n8n ai agent hat sich 2026 von der einfachen No-Code-Pipeline zur ernstzunehmenden Multi-Agenten-Infrastruktur für Unternehmen entwickelt. Durch das neue @n8n/agents SDK gelingt n8n der Spagat zwischen visueller Intuition und flexibler Code-First-Logik, was die Plattform zur führenden Open-Source-Alternative für komplexe KI-Orchestrierungen macht. Obwohl kollaborative Multi-Agenten-Systeme (Supervisor-Worker-Setups) laut aktuellen Benchmarks die Genauigkeit komplexer Aufgaben um 90,2 % steigern, droht durch den bis zu 15-fach höheren Token-Verbrauch eine Kostenexplosion. Unternehmen müssen daher trotz vorteilhafter n8n-Flattarife (wie den 40.000 Executions im Business-Tarif) ihre LLM-API-Budgets über strenge Guardrails aktiv managen.
Key Takeaways für Entscheider
Der n8n ai agent im Enterprise-Einsatz: Die native Integration in SAP Joule und die Bewertung von 5,2 Milliarden Dollar zeigen, dass n8n die Nische endgültig verlassen hat.
Multi-Agenten-Systeme schlagen RAG: Reine RAG-Pipelines sind Commodity; der echte Hebel liegt in spezialisierten Sub-Agenten, die über einen zentralen Orchestrator gesteuert werden.
Code-First-Erweiterung per SDK: Das @n8n/agents TypeScript SDK ermöglicht Entwicklern die programmatische Definition von Guardrails, Networks und Memory-Strukturen auf dem n8n-Server.
Die Token-Kostenfalle beherrschen: Während n8n nach Pauschal-Executions abrechnet, vervielfachen komplexe Schleifen und Worker-Aufrufe die externen API-Gebühren dramatisch.
Zustandsmanagement als n8n-Schwachstelle: Im direkten Vergleich zu LangGraph fehlt n8n ein natives State-Checkpointing zur Fehler-Isolation und für historische Rollbacks.
Datensouveränität durch Self-Hosting: Die selbst-hostbare Community Edition macht n8n zur datenschutzkonformen Alternative für sensible Unternehmensdaten.
Für wen lohnt sich der n8n ai agent? (Und für wen nicht?)
Nutze es, wenn:
Du ein pragmatischer Entwickler oder ein mittelständisches bis großes Unternehmen bist, das bereits hunderte APIs (wie Salesforce, HubSpot, Slack) nutzt und diese DSGVO-konform orchestrieren will.
Du visuelle Transparenz für Fachabteilungen benötigst, aber die Power eines TypeScript SDKs für komplexe Logik nicht missen willst. In diesem Szenario ist der n8n ai agent deine perfekte Wahl.
Lass es, wenn:
Du ein reiner Python-Purist bist, der hochkomplexe, zyklische Schleifen mit permanentem State-Checkpointing bauen muss – in diesem Fall bist du bei Frameworks wie LangGraph besser aufgehoben.
Du völlig ohne Budget und ohne technisches Verständnis „KI-Agenten“ zusammenklicken willst. Ohne präzise Tool-Beschreibungen und saubere System-Prompts scheitern autonome Agenten in der Praxis gnadenlos.
Die strategische Einordnung (FAQ Bridge)
Wie in den FAQ beleuchtet, löst n8n zwar das Plattform-Kostenproblem durch sein Flat-per-Execution-Modell, verlagert das finanzielle Risiko aber auf die LLM-Schnittstellen. Wer datenschutzkonforme On-Premise-Setups aufbauen will, findet hier dank der Community Edition und lokaler LLM-Integrationen jedoch eine unschlagbare Lösung, die Zapier und Co. alt aussehen lässt. Der n8n ai agent bleibt der vielseitigste Hybrid-Ansatz auf dem Markt, weil er visuelle API-Orchestrierung nahtlos mit Code-First-Agenten-Logik verbindet, was es für zukunftsorientierte Unternehmen unumgänglich macht, diese Technologie jetzt zu evaluieren und in ihre Automatisierungs-Roadmap zu integrieren.
Florian Schröder ist Experte im Online-Marketing mit Schwerpunkt PPC (Pay-Per-Click) Kampagnen. Die revolutionären Möglichkeiten der KI erkennt er nicht nur, sondern hat sie bereits fest in seine tägliche Arbeit integriert, um innovative und effektive Marketingstrategien zu entwickeln.
Er ist überzeugt davon, dass die Zukunft des Marketings untrennbar mit der Weiterentwicklung und Nutzung von künstlicher Intelligenz verbunden ist und setzt sich dafür ein, stets am Puls dieser technologischen Entwicklungen zu bleiben.
Wir verwenden Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wir tun dies, um das Surferlebnis zu verbessern und um personalisierte Werbung anzuzeigen. Wenn Sie diesen Technologien zustimmen, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn Sie Ihre Zustimmung nicht erteilen oder zurückziehen, können bestimmte Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.