Finetuning ermöglicht, dass ein Sprachmodell eigene Daten dazuzulernt. Dies verbessert die Antwortqualität enorm. Hier zeigen wir, wie man OpenAIs GPT-Modell (3.5 Turbo oder GPT-4o) mit Finetuning deutlich verbessert. Dies geht via OpenAI-API oder Microsoft Azure. Highlight: Das komplette Jupyter-Notebook haben wir euch verlinkt.
Ein großes Sprachmodell (LLM) wie GPT-4o von OpenAI kann bereits viele Fragen umfassend beantworten. Jedoch liefert es ungenügende Antworten, wenn man spezielles Wissen abfragen will. Beispiele: Produkte eines Unternehmens, typische Hotline-Anfragen beantworten und mehr. Hier hilft Finetuning, denn man kann fehlendes Wissen für Aufgaben oder Branchen einfach nachtrainieren, ohne dass man sich ein eigenes Basismodell trainieren muss. Dies würde auch sehr schwierig werden, denn dies erfordert oft Highend-GPU-Hardware, Trainingsdaten und Spezialwissen. Finetuning ist genau dafür gemacht, ein Sprachmodell nachträglich noch präziser und zuverlässiger zu machen.
OpenAI nennt folgende Verbesserungen durch Finetuning:
Steuerbarkeit: Durch Finetuning reagiert das Modell genauer auf Anweisungen, wie etwa die festgelegte Sprache. Dies verhindert, dass Chatbots abschweifen, was gelegentlich passieren kann.
Konsistente Formatierung: Das finegetunete Modell liefert bessere Antworten im beliebigen Format, ideal für technische Anwendungen wie Code-Generierung (Beispiel: eine Python- oder JSON-Datei erzeugen)
Markentonalität: Das Chat-Modell spricht in der speziellen Tonalität eines Unternehmens, was die Markenidentität stärkt (z.B. siezen vs. duzen, locker vs. seriös, inspirierend vs. faktenbasiert etc)
Prompt-Einsparung: Durch Finetuning kann man auch API-Kosten und Aufwände für Prompts sparen. Denn wenn das Finetuning-Modell genau weiss, was es machen soll, können „bis zu 90% der Token-Kosten eingespart werden“ (Beispiel von OpenAI genannt, frei übersetzt).
Kosten für Finetuning-Modelle
Die Kosten für das Training und die Nutzung der Finetuning-Modelle von OpenAI werden nach Tokens berechnet. 1000 Tokens ensprechen ca. 750 englischen Wörtern. Im Vergleich zum normalen Basismodell kostet das Finetuning-Modell ca. 3x mehr bei der Eingabe, 4x mehr bei der Ausgabe. Das Training kostet extra.
Für ein Trainins-File mit 100,000 Tokens (trainiert über 3 Epochen), wären die geschätzten Kosten ca 1 € mit gpt-4o-mini-2024-07-18
Aktuelle Preisinformationen findet man in den OpenAI API docs
Beispiele: So hilft Finetuning
Insgesamt verbessert Feintuning die KI-Modelle, indem diese damit ihre Aufgaben zuverlässiger und genauer erfüllen können. Es geht nicht nur darum, KI schlauer zu machen, sondern sie auch relevanter und wertvoller für den Endnutzer zu machen. Hier einige Beispiele aus der Praxis.
Besserer Chatbot-Kundensupport: Durch Feintuning kann ein Chatbot firmenspezifische Informationen in seine Antworten einbeziehen. Zum Beispiel könnte er sagen: „Bitte sehen Sie nach, welche Produkt-ID auf der Originalverpackung des T-301-Mobiltelefons aufgedruckt ist“, um Kunden effektiv zu helfen.
Bessere Inhalte: Redaktionsteams können ihren Chatbot wie z.B. GPT-3.5 so trainieren, dass es den spezifischen Ton und Stil ihres Publikums trifft. Das bedeutet, dass Inhalte, die von der KI generiert werden, besser zur Zielgruppe passen und authentischer wirken.
Verbesserte Übersetzungen: Für Unternehmen, die in bestimmten geografischen Regionen tätig sind, kann das Modell so angepasst werden, dass es regionale Sprachnuancen oder branchenspezifischen Jargon besser erfasst und übersetzt. Beispiel: Januar heisst in Österreich „Jänner“.
Optimierter Kundenservice: Ein feinabgestimmtes Modell kann Kundenanfragen besser verstehen und genauer darauf reagieren. Dies kann dazu führen, dass Kunden schneller und zufriedenstellender Antworten erhalten, was die Kundenzufriedenheit erhöht.
Datenschutz und Compliance: Durch Feintuning kann das Modell so trainiert werden, dass es bestimmte Informationen oder Daten vermeidet, die für ein Unternehmen heikel sein könnten. Dies ist besonders wichtig für Branchen, die strenge Datenschutzbestimmungen einhalten müssen.
Möglichkeiten der Umsetzung
Man kann das GPT-Modell über die OpenAI-API oder über Microsoft Azure OpenAI Service nutzen.
Zunächst zeigen wir, wie dies mit der OpenAI-API funktioniert. Am einfachsten kann man das Fine-tuning a) über die das Frontend des OpenAI Playgrounds nutzen, was schnell und einfach geht. Alternativ könnt ihr dies auch b) per Python-Code erreichen, was den Vorteil hat, dass ihr das Fine-tuning in eure eigenen Build-Prozesse einklinken könnt.
Danach skizzieren wir kurz den Weg via Microsoft Azure OpenAI.
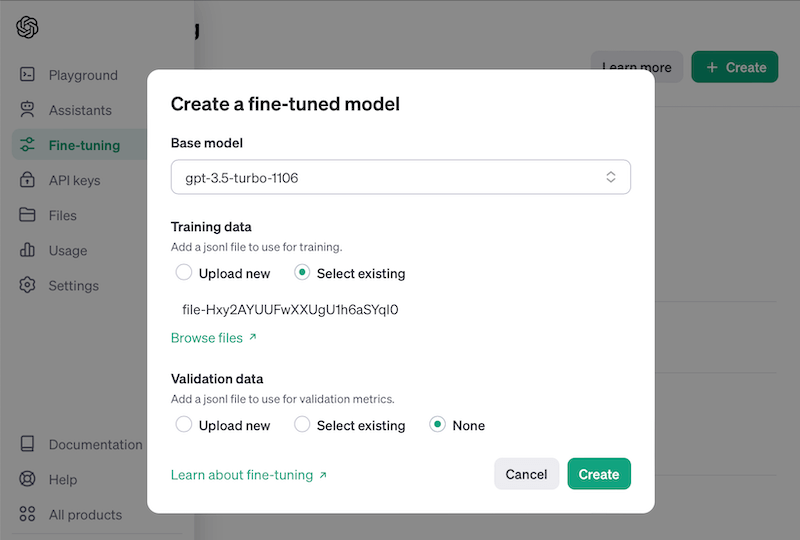
Variante 1: Fine-tuning von GPT via OpenAI Playground
Basis-Modell wählen (z.B.: gpt-3.5-turbo-1106 oder gpt-4o)
Trainingsdaten hochladen (unter „Variante 2“ lest ihr mehr dazu, wie man diese erstellt)
Validierungsdaten hochladen (optional, ermöglicht messen der Verbesserung durch Fine-tuning)
Click auf „Create“
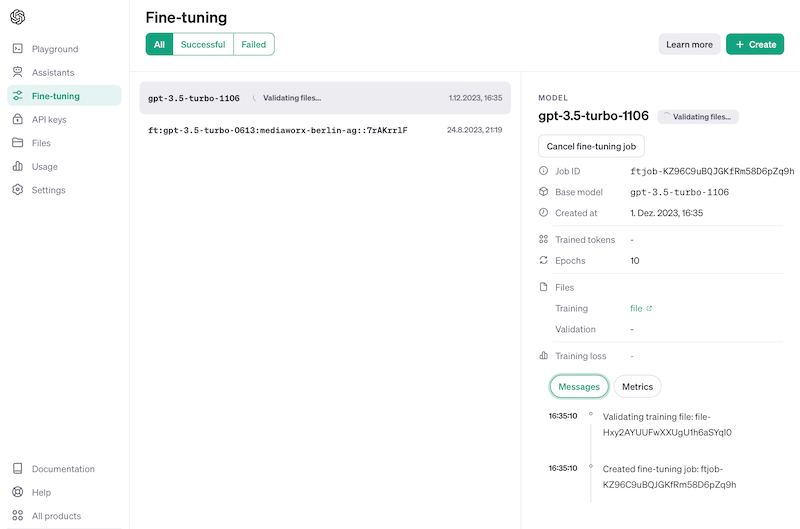
Warten (ca. 10 min, abhängig von Trainingsdatenmenge)
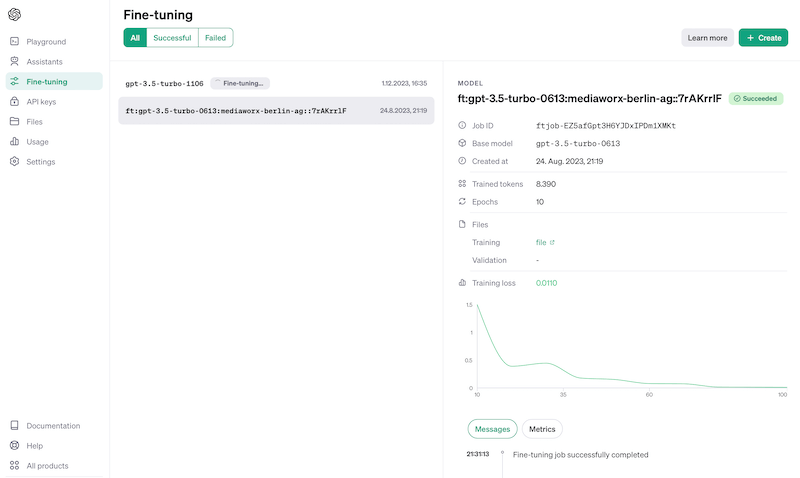
Click auf „Playground“ links
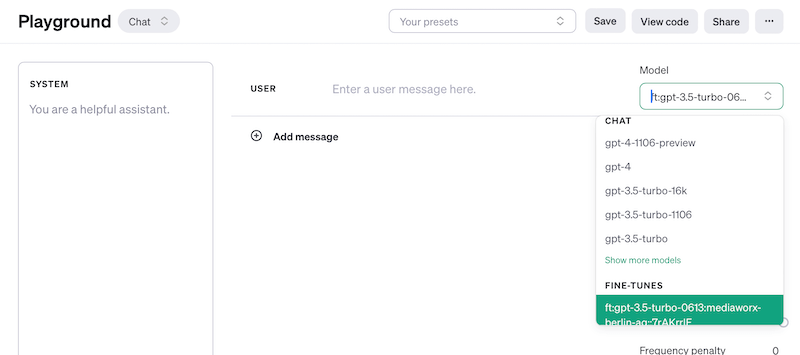
Das Fine-getunete Modell steht nun dauerhaft im Playground zur Verfügung und ihr könnt es dort im Chat direkt nutzen oder alternativ per API ansprechen.
Konfiguration des Fine-tuning-Modells:
Trainieren: Man sieht, wie weit das Modell bereits trainiert ist und kann Fehler erkennen
Ergebnis: Fertig trainiertes Modell
Fine-tuning-Modell nutzen: Im Playground oder per API
Variante 2a: Fine-tuning von GPT via Python und OpenAI-API
Dauer: 30 Minuten (je nach Erfahrung), Empfohlen für: Python-Coder
Fine-tuning kann mit OpenAIs GPT-Modell (Beispiel: GPT 3.5 Turbo und aufwärts) mit wenigen Code-Zeilen umgesetzt werden. Die OpenAI-API kann man per curl oder Python aufrufen. Da LLM-Developer überwiegend mit Python arbeiten zeigen wir hier ein Beispiel, wie man Fine-tuning per Jupyter-Notebook ausführt.
Schritte zum Fine-tuning via Python-Code:
Daten vorbereiten
Daten zu OpenAI hochladen
Finetuning-Job starten
Finetuning-Modell abfragen
Los gehts.
Schritt 0: Vorbereitung des Jupyter-Notebooks und der Imports
Wir nutzen JupyterLab als IDE. Man kann den Code jedoch auch in Google Colab nutzen, muss dann jedoch die Datei mit den Trainingsdaten per Google Drive hochladen und Colab mit Google Drive verbinden.
JupyterLab: Python-Notebook für das GPT-Finetuning im Überblick
Zuerst werden notwendige Libraries installiert. Danach sollte man den Jupyter-Kernel neu starten (via Menü unter Kernel > Restart Kernel). Die Libraries werden importiert und API-Variablen gesetzt. Ihr braucht euren OpenAI-API-Key und die Organisations-ID. Diese findet man im OpenAI-Account.
# upgrade openai library, restart kernel
pip install --upgrade openai
# imports and settings
import os
import openai
import json
import datetime
OPENAI_API_KEY = "sk-12345" # TODO: Enter API key
ORG_ID = "org-12345" # TODO: Enter Org ID
TRAINING_FILE_NAME = "data-finetuning-10examples.jsonl" # training file in JSONL format
# set API key
openai.api_key = OPENAI_API_KEY
Schritt 1: Finetuning-Daten vorbereiten
Finetuning-Trainingsdaten bereitet man in Frage/Antwort-Form auf, damit das GPT-Modell diese klar lernen kann. Als Beispiel verbessern wir einen Kundenservice-Chatbot. Dafür haben wir uns Dummy-Kundenservice-Daten per ChatGPT mit GPT-4 im benötigten Format generiert (Prompt: siehe Notebook).
Dummy-Daten für das Finetuning mit ChatGPT generieren
Wie sollten die Finetuning-Trainingsdaten aufbereitet sein?
Die OpenAI-API erfordert mindestens 10 Beispiele für das Finetuning. Im wirklichen Einsatz braucht man deutlich mehr Trainings-Daten. Als Fausregel könnten hier 50-100 Beispiele eine gute Orientierung sein, empfiehlt OpenAI:
„We typically see clear improvements from fine-tuning on 50 to 100 training examples with gpt-3.5-turbo but the right number varies greatly based on the exact use case.“ Quelle: OpenAI
Generell ist bei Trainingsdaten zu beachten, dass man Trainingsdaten mit guter Qualität nutzt, die also möglichst korrekt, klar, widerspruchsfrei, vollständig und gut maschinenlesbar sind. Dies ist wichtiger, als möglichst viele Trainingsdaten einzuspielen. Die OpenAI-API kann die Daten im JSONL-Format einlesen.
Finetuning-Daten bestehen aus Frage/Antwort-Beispielen
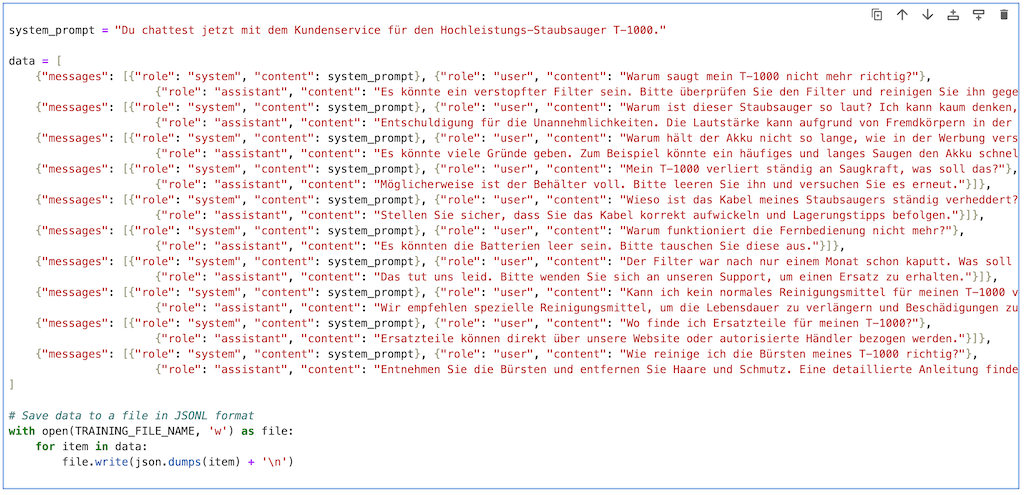
Der Python-Code zum Definieren der Finetuning-Trainingsdaten (Ausschnitt):
system_prompt = "Du chattest jetzt mit dem Kundenservice für den Hochleistungs-Staubsauger T-1000."
data = [
{"messages": [{"role": "system", "content": system_prompt}, {"role": "user", "content": "Warum saugt mein T-1000 nicht mehr richtig?"},
{"role": "assistant", "content": "Es könnte ein verstopfter Filter sein. Bitte überprüfen Sie den Filter und reinigen Sie ihn gegebenenfalls."}]},
{"messages": [{"role": "system", "content": system_prompt}, {"role": "user", "content": "Warum ist dieser Staubsauger so laut? Ich kann kaum denken, wenn er läuft!"},
{"role": "assistant", "content": "Entschuldigung für die Unannehmlichkeiten. Die Lautstärke kann aufgrund von Fremdkörpern in der Bürste steigen. Bitte überprüfen Sie diese."}]},
{"messages": [{"role": "system", "content": system_prompt}, {"role": "user", "content": "Warum hält der Akku nicht so lange, wie in der Werbung versprochen?"},
{"role": "assistant", "content": "Es könnte viele Gründe geben. Zum Beispiel könnte ein häufiges und langes Saugen den Akku schneller entladen. Stellen Sie sicher, dass Sie den Staubsauger nach jedem Gebrauch aufladen."}]},
{"messages": [{"role": "system", "content": system_prompt}, {"role": "user", "content": "Kann ich kein normales Reinigungsmittel für meinen T-1000 verwenden?"},
{"role": "assistant", "content": "Wir empfehlen spezielle Reinigungsmittel, um die Lebensdauer zu verlängern und Beschädigungen zu vermeiden."}]}
]
# Save data to a file in JSONL format
with open(TRAINING_FILE_NAME, 'w') as file:
for item in data:
file.write(json.dumps(item) + '\n')
Schritt 2: Trainingsdaten hochladen
Als nächstes laden wir die Trainingsdaten als Datei über die OpenAI API hoch. Wichtig: Keine sensiblen Daten hochladen. Die TRAINING_FILE_ID brauchen wir, um damit im nächsten Schritt das Finetuning zu starten.
response_upload = openai.File.create(
file=open(TRAINING_FILE_NAME, "rb"), purpose='fine-tune'
)
TRAINING_FILE_ID = response_upload.id
# print upload response to check if successful
response_upload
Schritt 3: Finetuning-Job starten
Nun wird der Finetuning-Job gestartet und das Modell wird trainiert.
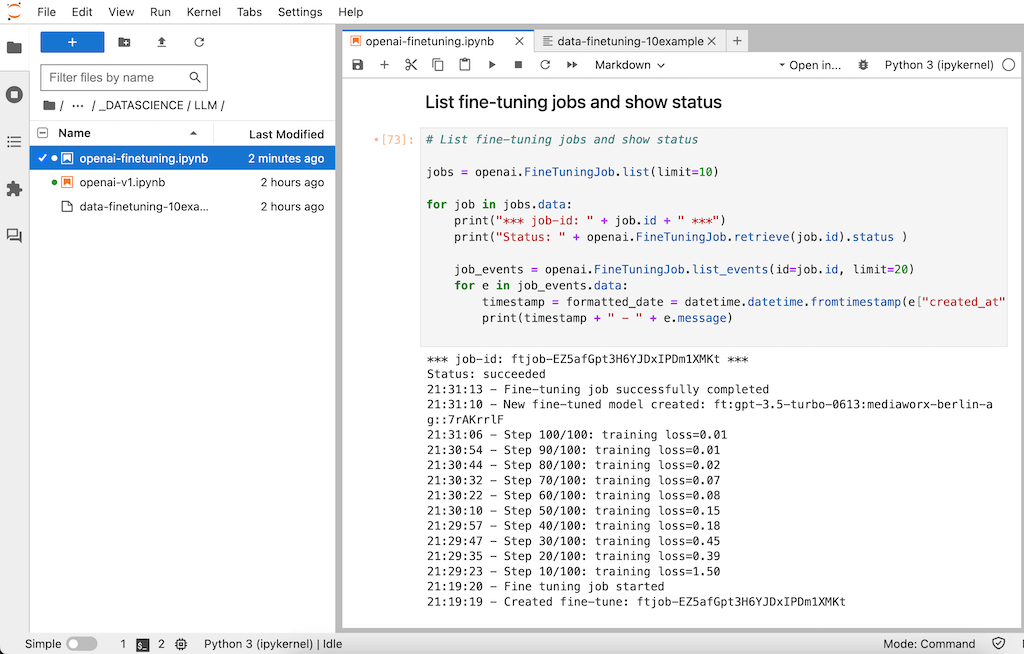
Dieser Vorgang dauert bei unseren 10 Dummy-Einträgen ca. 12 Minuten. Man kann jederzeit prüfen, wie weit der Vorgang bereits fortgeschritten ist. Dazu kann man sich die alle laufenden Fine-Tuning-Jobs mit ihren Job-Events auflisten lassen.
# List fine-tuning jobs and show status
jobs = openai.FineTuningJob.list(limit=10)
for job in jobs.data:
print("*** job-id: " + job.id + " ***")
print("Status: " + openai.FineTuningJob.retrieve(job.id).status )
job_events = openai.FineTuningJob.list_events(id=job.id, limit=20)
for e in job_events.data:
timestamp = formatted_date = datetime.datetime.fromtimestamp(e["created_at"]).strftime('%H:%M:%S')
print(timestamp + " - " + e.message)
Das Ergebnis nach einem erfolgreich durchgeführtem Finetuning sieht wie folgt aus:
Finetuning mit GPT: Job-Status nach erfolgreichem Finetuning
Schritt 4: Finetuning-Modell abfragen
Nach erfolgreich abgeschlossenem Finetuning steht euch euer eigenes Modell zur Verfügung. Dies hat den Namen „ft:“ wie „finetuning“, gefolgt vom verwendeten Basismodell (hier „gpt-3.5-turbo-0613“) und dem Organisationsnamen aus eurem OpenAI-Account, sowie einer 8-stelligen ID.
MODEL = "ft:gpt-3.5-turbo-0613:YOURORGNAME::7rAKrrlF"
completion = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "Du chattest jetzt mit dem Kundenservice für den Hochleistungs-Staubsauger T-1000."},
{"role": "user", "content": "Ich will meinen T-1000 mit Pril reinigen. Geht das?"}
]
)
print(completion.choices[0].message)
Das Ergebnis: Der Kundenservice-Chatbot antwortet präziser
Wir fragen unseren Kundenservice-Chatbot nun, ob wir unseren Staubsauger mit Pril reinigen können. Diese Anfrage sollte er entsprechend den Trainingsdaten so beantworten, dass er eher ein spezielles Reinigungsmittel empfiehlt. Wir haben die Anfrage bewusst so formuliert, dass GPT diese nicht 1:1 aus den Trainingsdaten ablesen kann.
Finetuning-Trainingsdaten:
Kunde: „Kann ich kein normales Reinigungsmittel für meinen T-1000 verwenden?“
Service: „Wir empfehlen spezielle Reinigungsmittel, um die Lebensdauer zu verlängern und Beschädigungen zu vermeiden.“
Antwort des Finetuning-Modells:
Kunde: Ich will meinen T-1000 mit Pril reinigen. Geht das?
Service: Wir empfehlen nur spezielle Reinigungsmittel, um Beschädigungen zu vermeiden.
So wird das finale fine-getunete Modell via Python befragt:
Finetuning mit GPT: Das Ergebnis: Der Kundenservice-Chat empfiehlt analog der Trainingsdaten
Variante 2b) Reinforcement-Finetuning von GPT 4.1 per API
Als verbessertes Finetuning-Verfahren bietet OpenAI ab Modell GPT-4.1 das Reinforcement-Finetuning an. Diese Option steht derzeit als API zur Verfügung, muss also gecoded werden. Reinforcement Fine-Tuning (RFT) ermöglicht es, OpenAI-Modelle mit einem programmierbaren Grader (Ergebnis: Prozentwert zwischen 0 und 1) statt festen Labels (Ergebnis: 0 oder 1) zu optimieren, sodass das Modell gezielt auf individuelle Qualitätsmetriken wie Stil, Sicherheit oder Domänenwissen ausgerichtet („fine-tuned“) werden kann.
Entwickler definieren dafür einen Grader,
laden Trainings- und Testdaten hoch und
starten den Fine-Tuning-Job,
das Modell wird anhand der Grader-Scores iterativ angepasst.
Besonders praktisch: RFT eignet sich ideal, um LLMs für strukturierte Ausgaben (z.B. JSON) und anspruchsvolle Spezialaufgaben fit zu machen, indem die Trainingsschleife bis zum optimalen Ergebnis automatisiert durchlaufen wird.
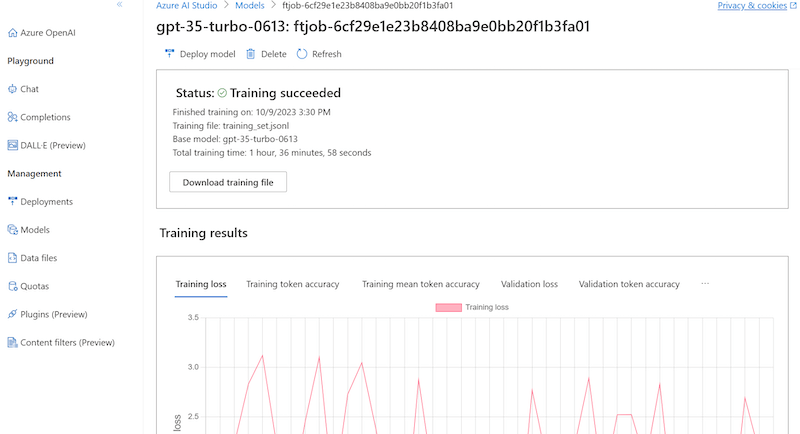
Variante 3: Fine-tuning von GPT via Microsoft Azure OpenAI
Wer die für viele Unternehmen datenschutzkonformere Lösung über Microsoft Azure nutzt, kann sein GPT-Modell ebenfalls komfortabel fine-tunen. Auch hier gibt es beiden Methoden: entweder einfach über das Web-Frontend des Azure OpenAI Studios oder per Python-Code über die Azure-OpenAI-API.
Finetuning macht Sprachmodelle genauer und lässt sich sehr einfach nachträglich Modelle anwenden, die diese Technik unterstützen (z.B. GPT). Jedoch können – so wie bei allen Trainingsprozessen – auch Probleme auftauchen, die man daher kennen sollte.
Datenqualität und -vielfalt: Das Modell ist nur so gut wie die Daten, mit denen es trainiert wird. Unzureichende, verzerrte oder nicht repräsentative Finetuning-Trainingsdaten können zu schlechter Leistung führen. Man sollte also einen Mix guter Antworten in den Finetuning-Daten kombinieren und sicherstellen.
Overfitting: Fine-Tuning mit einer zu spezifischen oder begrenzten Datenmenge kann dazu führen, dass das Modell zu stark auf diese speziellen Daten ausgerichtet ist („overfitting“) und darum dann schlechter auf allgemeinere oder neue Daten reagiert.
Catastrophic Forgetting: Ein interessantes Phänomen beim Finetuning ist das komplette Vergessen eigentlich bekannter Informationen und Antwortfähigkeiten. Dies kann auftreten, wenn das neuronale Netzwerk seine Gewichte anpasst, um neue Daten zu lernen, dabei jedoch die Anpassungen verliert, die für die Vorhersage der zuvor gelernten Daten wichtig waren. So kann selbst GPT-4 dann einige der beeindruckenden Fähigkeiten verlernen.
Ethik und Verzerrung: Sprachmodelle können bestehende soziale und kulturelle Vorurteile widerspiegeln. Dies kann zu Rassismus, Sexismus und andere Formen von Diskriminierung führen. Darum sollte man umfangreiche Finetuning-Daten und das neu trainierte Modell daraufhin abprüfen.
Fazit
Finetuning verbessert die Leistung des eh schon mächtigen GPT-Modells noch weiter und ist sehr leicht umsetzbar.
Finetuning ist mit ChatGPT 4o seit August 2024 möglich
Es gibt auch mit Finetuning keine absolute Kontrolle über die Ausgabe eines Frage/Antwort-Systems wie einen Chatbot. Doch verbessert das Finetuning die Qualität deutlich und bietet viel mehr Stabilität. Die Ergebnisse des Finetunings sollten darum vor dem Einsatz sauber per Qualitätssicherung und Modell-Evaluation abgetestet werden.
Beim Training sollte man zudem berücksichtigen, keine sensiblen Daten an die OpenAI-API zu senden.
Bonus: Jupyter-Notebook zum Finetuning des GPT-Modells
Hier der Link zum Notebook inklusive Dummy-Trainingsdaten:
Ralf Schukay liebt Analytics, Python & alles mit Daten. In seiner Freizeit spielt er Synthesizer (Nord, Novation), joggt und fährt Gravel Bike. Er arbeitet als Teamlead Analytics & Conversion mit einem fitten und netten Team in der Berliner Digitalagentur >MAI mediaworx<
Wir verwenden Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wir tun dies, um das Surferlebnis zu verbessern und um personalisierte Werbung anzuzeigen. Wenn Sie diesen Technologien zustimmen, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn Sie Ihre Zustimmung nicht erteilen oder zurückziehen, können bestimmte Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.