Die PyData Global findet am 6.-8.12.2023 statt. Hier werden die wichtigsten Data- und AI-Themen praktisch mit Python und vielen weiteren Open-Source-Technologien vermittelt. Wir geben einen Überblick.
Überblick über die wichtigsten Data-Technologien und Themen
Wer sich im Unternehmen oder privat mit Data, Python und AI beschäftigt, braucht einen Überblick über viele Spezialisierungen. Hier kommt die PyData Global gerade recht, denn sie deckt tatsächlich ein riesiges Spektrum der dafür wichtigen Felder ab. Besonders hilfreich ist, dass der Schwerpunkt auf Open-Source-Technologien liegt, so dass man hier keine Kosten-Einstiegshürden hat.
Die Schwerpunkte der PyData sind:
Data Engineering
Machine Learning
Data Visualization
Large Language Models
Generelle Data-Themen Anwendungsgebiete
Wir haben euch die Schwerpunkte in praktische Themengebiete aufgeteilt und die wichtigsten Technologien zusammengefasst und verlinkt. So könnt ihr, auch ohne schon auf der Konferenz gewesen zu sein lernen, was die heissen Themen sind.
Thema 1: Data
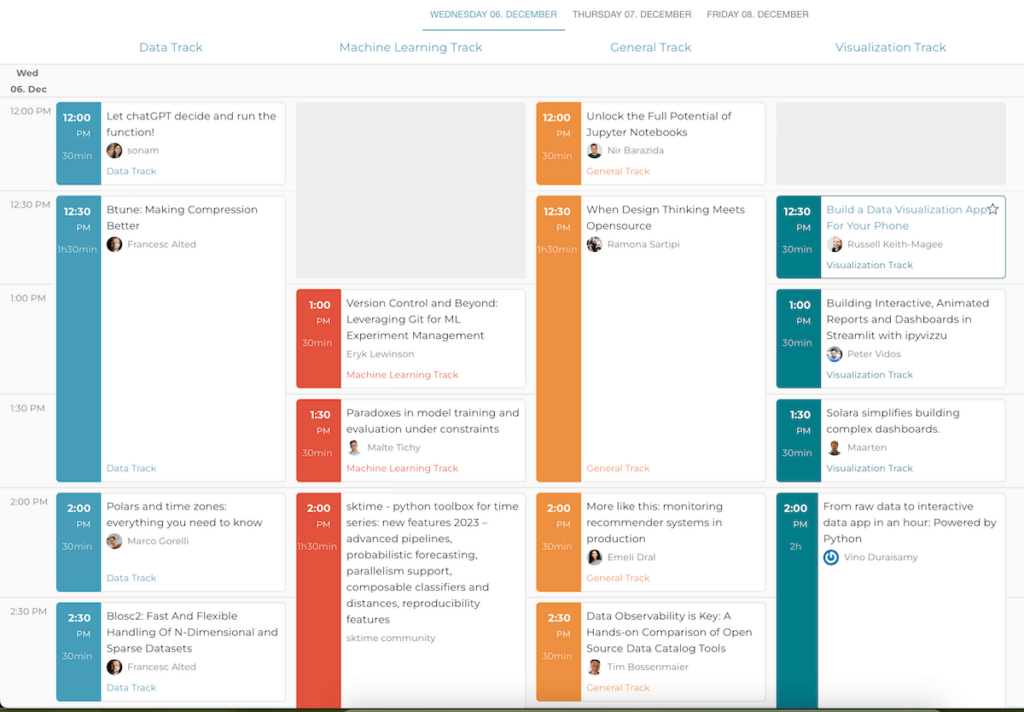
Datenverarbeitung und Leistungsoptimierung Hier dreht sich alles um effiziente Datenverarbeitung und Optimierung. Die Sessions beleuchten die neuesten Entwicklungen in beliebten Frameworks wie Pandas, Dask, und Polars. Es werden Lösungen rund um riesige Datensätze, GPU-Beschleunigung und Python-Workflows zur Datenverarbeitung gezeigt.
Sessions:
All Them Data Engines: Pandas, Spark, Dask, Polars and more – Data Munging with Python circa 2023
An Introduction to Pandas 2, Polars, and DuckDB
Pandas 2, Dask or Polars? Quickly tackling larger data on a single machine
Data of an Unusual Size: A practical guide to analysis and interactive visualization of massive datasets
Optimize first, parallelize second: a better path to faster data processing
cudf.pandas: The Zero Code Change GPU Accelerator for Pandas
We rewrote tsfresh in Polars and why you should too
Innovative Anwendungen und Datenhandling-Techniken Von der Verbesserung von Datenkompression mit Btune und Blosc2 bis hin zu den neuesten Entwicklungen in FastAPI für Data Engineers und Scientists, bieten diese Sessions Einblicke in spannende neue Tools und Methoden zur Datenverarbeitung. Zudem wird mit LanceDB eine Vector-Datenbank für Text/Bild/Audio/Multimodal-KIs vorgestellt.
Sessions:
Btune: Making Compression Better
Blosc2: Fast And Flexible Handling Of N-Dimensional and Sparse Datasets
How I used Polars to build functime, a next gen ML forecasting library
Arrow revolution in pandas and Dask
API development for data analysts/scientists with FastApi
LanceDB: lightweight billion-scale vector search for multimodal AI
Build AI-powered data pipeline without vector databases
Datenanalyse in speziellen Kontexten In diesem Bereich geht es um die Anwendung von Datenanalyse in spezifischen und manchmal unkonventionellen Kontexten. Die Themen reichen von Zeitzone-Handling mit Polars bis hin zu Klimadatenanalyse mit Xclim. Besonders interessant sind auch die Einblicke in Streaming-Daten und serverlose Systeme, die neue Horizonte in der Datenpersistenz und -verarbeitung eröffnen.
Sessions:
Polars and time zones: everything you need to know
How to build a data pipeline without data: Synthetic data generation and testing with Python
Data Tales from an Open Source Research Team
Real-Time Revolution: Kickstarting Your Journey in Streaming Data
Blazing fast I/O of data in the cloud with Daft Dataframes
High speed data from the Lakehouse to DataFrames with Apache Arrow
Production Data to the Model: “Are You Getting My Drift?”
Unified batch and stream processing in python
Data Harvest: Unlocking Insights with Python Web Scraping
Data persistence with consistency and performance in a truly serverless system
IID Got You Down? Resample Time Series Like A Pro
Kùzu: A Graph Database Management System for Python Graph Data Science
Xclim: Climate Data Processing and Analysis for Everyone
Thema 2: Machine Learning
Experimentmanagement und Bewertung im Machine Learning Der Fokus liegt hier auf der Verwaltung und Bewertung von ML-Experimenten. Sessions befassen sich mit der Anwendung von Versionierungswerkzeugen wie Git für ML, Probleme beim Modelltraining und ML-Toolboxen wie sktime. Es geht um die Balance zwischen technischer Raffinesse und pragmatischer Anwendbarkeit im ML-Bereich.
Sessions:
Version Control and Beyond: Leveraging Git for ML Experiment Management
Paradoxes in model training and evaluation under constraints
sktime – python toolbox for time series: new features 2023 – advanced pipelines, probabilistic forecasting, parallelism support, composable classifiers and distances, reproducibility features
Innovative Ansätze und Werkzeuge im Machine Learning Diese Kategorie zeigt innovative Methoden und Tools im ML. Themen umfassen die Verbesserung der Datenqualität, die Anwendung von Gaussian Processes, die Optimierung von scikit-learn Klassifikatoren, und die Konzeption von ML-Systemen für die Echtzeitwelt. Besonders interessant ist auch die Integration von lokalen LLMs und Code-Snippets in JupyterLab.
Sessions:
Improving Open Data Quality using Python
But what is a Gaussian process? Regression while knowing how certain you are
Enhancing your JupyterLab Developer Experience with Local LLMs and Code Snippets
Get the best from your scikit-learn classifier: trusted probabilties and optimal binary decision
Unravelling Hidden Technical Debt in ML: A Pythonic Approach to Robust Systems
DDataflow: An open-source end to end testing from machine learning pipelines
Event-Driven Data Science: Reconceptualizing Machine Learning for the Real-time World
Herausforderungen im Machine Learning Hier werden High-End Anwendungsbereiche und Herausforderungen im ML untersucht. Themen reichen von der Entwicklung robuster KI-Pipelines mit Hugging Face und Kedro bis hin zu Frameworks für das „Machine Unlearning“. Weitere Highlights sind die Maximierung der GPU-Nutzung für das Modelltraining und das Verständnis und die Überbrückung von klassischen ML-Pipelines und LLMs.
Sessions:
Who needs ChatGPT? Rock solid AI pipelines with Hugging Face and Kedro
Customizing and Evaluating LLMs, an Ops Perspective
How can a learnt ML model unlearn something: Framework for „Machine Unlearning“
Bridging Classic ML Pipelines with the World of LLMs
Compute anything with Metaflow
Full-stack Machine Learning and Generative AI for Data Scientists
Predictive survival analysis with scikit-learn, scikit-survival and lifelines
sktime – the saga. Trials and tribulations of a charitable, openly governed open source project
Modeling Extreme Events with PyMC
Introduction to Machine Learning Pipelines: How to Prevent Data Leakage and Build Efficient Workflows
Thema 3: General Track
Erweiterung und Optimierung von Werkzeugen und Methoden In diesem Bereich liegt der Fokus auf der Erweiterung und Optimierung bestehender Werkzeuge und Methoden. Von der vollen Ausschöpfung der Potenziale von Jupyter Notebooks bis hin zum Entwickeln von On-Demand-Logistik-Apps mit Python, es geht um innovative Anwendungen und Verbesserungen in der Handhabung von Daten und Software. Themen wie der Kampf gegen Geldwäsche mit Python und das Leben in einer, Achtung: _lognormalen_ Welt bieten spannende Einblicke in spezielle Fachwelten.
Sessions:
Unlock the Full Potential of Jupyter Notebooks
When Design Thinking Meets Opensource
More like this: monitoring recommender systems in production
Data Observability is Key: A Hands-on Comparison of Open Source Data Catalog Tools
Fighting Money Laundering with Python and Open Source Software
Cloud UX for Data People
Extremes, outliers, and GOATS: on life in a lognormal world
Map of Open-Source Science (MOSS)
VocalPy: a core Python package for acoustic communication research
Intake 2
The Hell, According to a Data Scientist
Order up! How do I deliver it? Build on-demand logistics apps with Python, OR-Tools, and DecisionOps
Getting better at Pokémon using data, Python, and ChatGPT.
Integration und Anwendung neuer Technologien Diese Kategorie zeigt, wie neue Technologien in bestehende Systeme integriert und effizient genutzt werden können. Es geht um das Brückenbauen zwischen Theorie und Praxis in Investmentportfolios, die Verbesserung der Laufzeitreproduzierbarkeit im Python-Ökosystem und die Anwendung von Julia in der Dezentralisierung. Auch interessant ist die Nutzung von Python für interaktive Datenwissenschaften und die Entwicklung von Workflows für akustische Fischereierhebungen.
Sessions:
Python-Driven Portfolios: Bridging Theory and Practice for Efficient Investments
FawltyDeps: Finding undeclared and unused dependencies in your notebooks and projects
The Internet’s Best Experiment Yet
Xorbits Inference: Model Serving Made Easy
Introduction to Using Julia for Decentralization by a Quant
HPC in the cloud
Architecting Data Tools: A Roadmap for Turning Theory and Data Projects into Python Packages
Ensuring Runtime Reproducibility in the Python Ecosystem
Prefect Workflows for Scaling Acoustic Fisheries Survey Pipelines
Collaborate with your team using data science notebooks
Python as a Hackable Language for Interactive Data Science
Quarto dashboards
Keras (3) for the Curious and Creative
Hands-On Network Science
NonlinearSolve.jl: how compiler smarts can help improve the performance of numerical methods
Thema 4: Visualization
Entwicklung interaktiver Datenvisualisierungs-Apps Im Zentrum steht die Entwicklung von interaktiven und Datenvisualisierungs-Apps mit guter Usability. Die Sessions behandeln die Mobile-App-Erstellung bis hin zu komplexen Dashboards und interaktiven Netzwerkgrafiken. Technologien wie Streamlit und Shiny stehen dabei im Vordergrund, die das Erstellen von animierten Berichten und Dashboards vereinfachen. Ästhetik und Funktionalität müssen zusammenspielen, damit wir die Daten verständlich darstellen können, egal wie komplex die Zusammenhänge auch sein mögen.
Sessions:
Build a Data Visualization App For Your Phone
Building Interactive, Animated Reports and Dashboards in Streamlit with ipyvizzu
Solara simplifies building complex dashboards.
From raw data to interactive data app in an hour: Powered by Python
Building an Interactive Network Graph to Understand Communities
Datenexploration vereinfachen Hier wird die wichtige Datenexploration durch visuelle Mittel verbessert. Neue Ansätze zeigen, wie man komplexe Datenmengen intuitiv und interaktiv erforschen kann. Dafür müssen komplexe Datenbeziehungen verständlich visualisieret werden. Sessions wie das Verständnis der reaktiven Ausführung in Shiny oder das Bauen interaktiver Netzwerkgrafiken bieten praktische Einblicke in die fortgeschrittenen Anwendungen von Visualisierungstechnologien.
Sessions:
Empowering Data Exploration: Creating Interactive, Animated Reports in Streamlit with ipyvizzu
Understanding reactive execution in Shiny
Thema 5: Large Language Models
Darauf haben wir gewartet. Natürlich gibt es keine Data/AI-Konferenz ohne LLMs.
Entwicklung und Einsatz von Large Language Models (LLMs) Dieser Track konzentriert sich auf die praktische Anwendung und Entwicklung von Large Language Models (LLMs). Von der Erstellung kontextbezogener Chatbots bis hin zum Training großmaßstäblicher Modelle mit PyTorch, diese Sessions decken ein breites Spektrum ab. Es geht darum, die Grenzen von LLMs zu erweitern und sie effektiv in der Praxis einzusetzen. Themen wie die Beschleunigung der Dokumentendeduplizierung für das Training von LLMs und die Produktionisierung von Open-Source-LLMs bieten tiefe Einblicke in die aktuellen Herausforderungen und Lösungen in diesem schnell wachsenden Bereich.
Sessions:
Building Contextual ChatBot using LLMs, Vector Databases and Python
Accelerating fuzzy document deduplication to improve LLM training with RAPIDS and Dask
LLMs: Beyond the Hype – A Practical Journey to Scale
Productionizing Open Source LLMs
Leveraging open-source LLMs for production
From RAGs to riches: Build an AI document interrogation app in 30 mins
Training large scale models using PyTorch
Erweiterte Anwendungen und Geschäftsnutzen von LLMs In dieser Kategorie liegt der Fokus auf den erweiterten Anwendungen von LLMs und ihrem potenziellen Geschäftsnutzen. Es werden Ansätze vorgestellt, um LLMs für spezifische Anwendungen wie die Verbesserung von Search Engines und Learning-to-Rank-Modellen zu nutzen. Zudem ermöglichen generative AI-Workflows bessere Ergebnisse im Unternehmen.
Sessions:
Building Learning to Rank models for search using Large Language Models
Using Large Language Models to improve your Search Engine
Orchestrating Generative AI Workflows to Deliver Business Value
Fazit: Die Data-Themen der Zukunft
Mit dieser beeindruckenden Auswahl an Sessions, die von der Feinheiten der Datenverarbeitung bis hin zu neuartigen Anwendungen von Large Language Models reichen, stellt diese Konferenz eine wahre Schatztruhe des Wissens dar. Die Sessions bieten Einblicke in die Spitze der technologischen Entwicklung. Zudem wird hier eine inspirierende Gemeinschaft von Gleichgesinnten zusammengebracht, die gemeinsam die Zukunft von Data & künstlicher Intelligenz mitgestalten.
Ralf Schukay ist Co-Gründe von ai-rockstars und spezialisiert auf AI Engineering und Data Analytics. Er arbeitet als Teamlead Analytics & Conversion mit einem fitten und netten Team in der Berliner Digitalagentur >MAI mediaworx< und füllt seine Freizeit mit Familienaktivitäten rund um Berlin, CrossFit, Gravel Bike und Synthesizern.
Wir verwenden Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wir tun dies, um das Surferlebnis zu verbessern und um personalisierte Werbung anzuzeigen. Wenn Sie diesen Technologien zustimmen, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn Sie Ihre Zustimmung nicht erteilen oder zurückziehen, können bestimmte Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.








")
