Die Veröffentlichung des Hunyuan-Large Modells von Tencent markiert einen wichtigen Meilenstein im Bereich der großskaligen Sprachmodelle. Diese Neuerung ist nicht nur technisch beeindruckend, sondern zeigt auch, wie offen verfügbarer Code die Innovationsgeschwindigkeit in der KI-Forschung steigern kann.
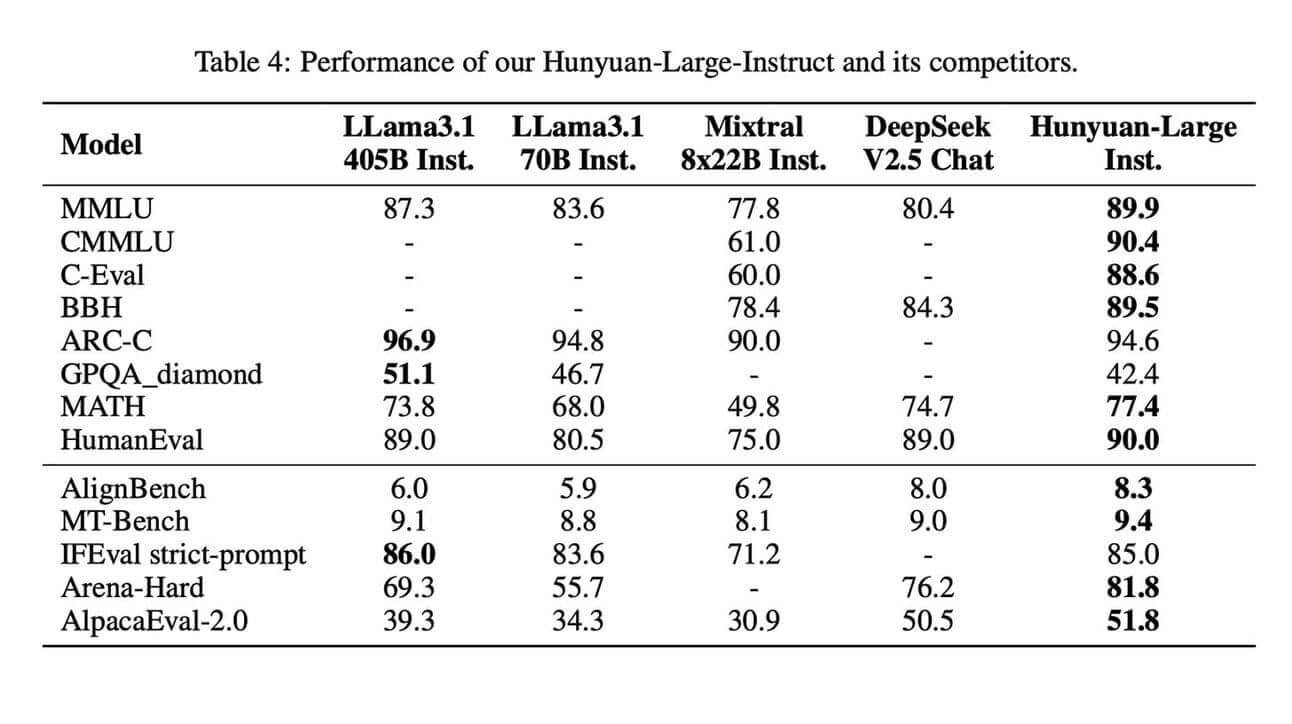
Das Hunyuan-Large-Modell basiert auf einem Transformer-gestützten Mixture of Experts (MoE)-Ansatz, der es ermöglicht, effizient zu skalieren, indem jeweils nur ein Teil der 389 Milliarden Parameter für Eingaben aktiviert wird. Dies reduziert nicht nur die Rechenkosten, sondern verbessert auch die Modellleistung in Aufgaben der Sprachverständnis, -erzeugung, logischem Denken und mehr. Mit 52 Milliarden aktivierten Parametern stellt es das größte offene MoE-Modell seiner Art dar und übertrifft damit leistungsstarke Modelle wie das LLama3.1-70B.
Ein wesentlicher technischer Fortschritt ist die Verwendung stark vergrößerter synthetischer Trainingsdaten, die die Leistung von Hunyuan-Large erheblich steigern. Ergänzt wird dies durch eine innovative gemischte Expertenrouting-Strategie, die für optimale Verteilung der Eingaben sorgt, sowie durch ein Schlüssel-Wert-Cache-Kompressionsverfahren, das den Speicherverbrauch reduziert.
Verfügbarkeiten und rechtliche Überlegungen
Hunyuan-Large ist öffentlich zugänglich, um die Weiterentwicklung in der KI-Community zu fördern. Während die Offenlegung solcher großen Modelle Fragen zu geistigen Eigentumsrechten aufwirft, ermöglicht sie auch neue Diskussionen über die künftige Schaffung spezifischer Rechtsrahmen. Geografische Einschränkungen, wie der Ausschluss der Europäischen Union von bestimmten Nutzungsrechten, eröffnen zudem Raum für rechtliche Debatten in der internationalen KI-Governance.
Die Veröffentlichung eines Modells dieser Größenordnung wirft das Potenzial auf, zukünftige Forschungen und praktische Anwendungen in der natürlichen Sprachverarbeitung umfassend zu beeinflussen. Die Balance zwischen offenem Zugang und rechtlicher Schutz ist eine kritische Diskussion, die Anpassungen an bestehende und neue Entwicklungen erfordert.
Auswirkungen und Diskussion
Hunyuan-Large hat das Potenzial, die Forschungen in verschiedenen wissenschaftlichen und industriellen Bereichen neu zu definieren. Professionelle Diskussionen könnten sich auf die technischen Lösungen fokussieren, die hinter der erfolgreichen Skalierung solcher Modelle stehen. Besonders bemerkenswert ist, dass durch umfangreiche Trainingsdaten und spezialisierte Strategien zur Lernratenanpassung weitere Optimierungen bei der Entwicklung künftiger Open-Source-Modelle ermöglicht werden.
Die wichtigsten Fakten zum Update:
Größtes offenes MoE-Modell mit 52 Milliarden aktivierten Parametern.
Leistungen übertreffen bestehende Modelle durch neue Daten- und Routing-Techniken.
Förderung durch offenen Zugang, jedoch mit geografischen Einschränkungen.
Rechtliche Fragen zu Urheberrecht und geistigem Eigentum im Fokus.
Potenzielle Neuerfindung der Forschung und Anwendungen in der nativen Sprachverarbeitung.
Florian Schröder ist Experte im Online-Marketing mit Schwerpunkt PPC (Pay-Per-Click) Kampagnen. Die revolutionären Möglichkeiten der KI erkennt er nicht nur, sondern hat sie bereits fest in seine tägliche Arbeit integriert, um innovative und effektive Marketingstrategien zu entwickeln.
Er ist überzeugt davon, dass die Zukunft des Marketings untrennbar mit der Weiterentwicklung und Nutzung von künstlicher Intelligenz verbunden ist und setzt sich dafür ein, stets am Puls dieser technologischen Entwicklungen zu bleiben.
Wir verwenden Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wir tun dies, um das Surferlebnis zu verbessern und um personalisierte Werbung anzuzeigen. Wenn Sie diesen Technologien zustimmen, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn Sie Ihre Zustimmung nicht erteilen oder zurückziehen, können bestimmte Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.