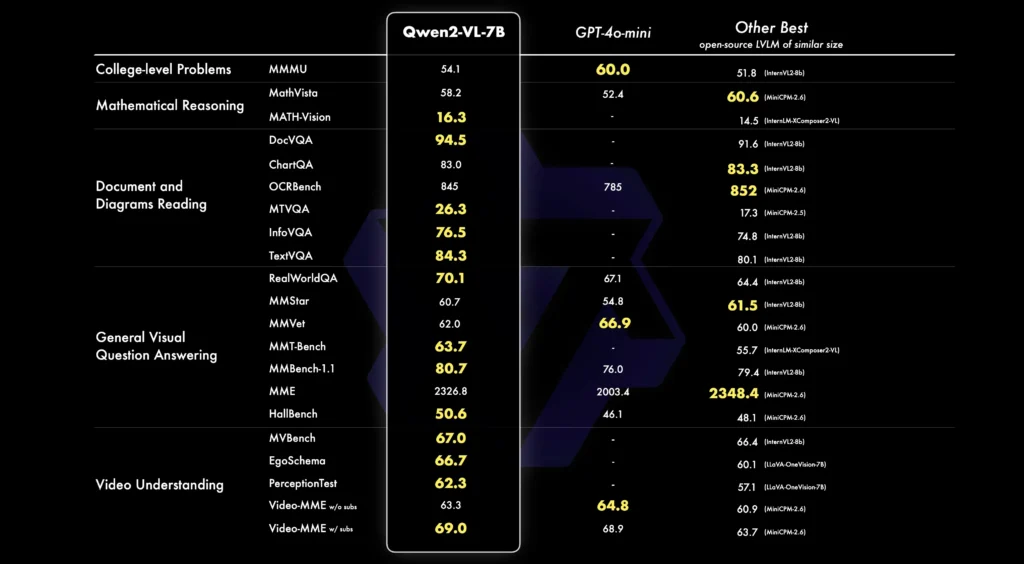
Alibaba hat sein neuestes KI-Modell Qwen2-VL vorgestellt, das die Analyse von Videos über 20 Minuten revolutioniert. Diese Innovation markiert einen bedeutenden Fortschritt in der Fähigkeit von KI, visuelle Inhalte umfassend zu verstehen und zusammenzufassen.
Mit fortschrittlichen Bildanalysefähigkeiten kann der Qwen2-VL nicht nur Bilder in Videos interpretieren, sondern auch detaillierte Zusammenfassungen und Antworten auf Fragen zum Inhalt liefern. Dies ist besonders im Kontext von Big Data und der enormen Menge an Videoinhalten, die täglich erstellt werden, äußerst vorteilhaft. Die Fähigkeit, relevante Informationen aus langen Videomaterialien zu extrahieren, könnte Branchen wie Medien, Sicherheit und Bildung erheblich beeinflussen.
qwen2-vl-7b
Die Einführung von Qwen2-VL spiegelt wider, wie schnell sich die Technologie in der Bild- und Videoanalyse entwickelt. Frühere Modelle waren oft auf kürzere Videoclips beschränkt oder konnten nur oberflächliche Analysen durchführen. Mit der Möglichkeit, längere Videos zu analysieren, eröffnet sich ein breites Spektrum an Anwendungen, von der Überwachung über Clouds basierende Inhaltsanalysen bis hin zu Echtzeit-Feedback in Bildungsanwendungen.
Außerdem gibt es zwei wichtige Aktualisierungen der Modellarchitektur:
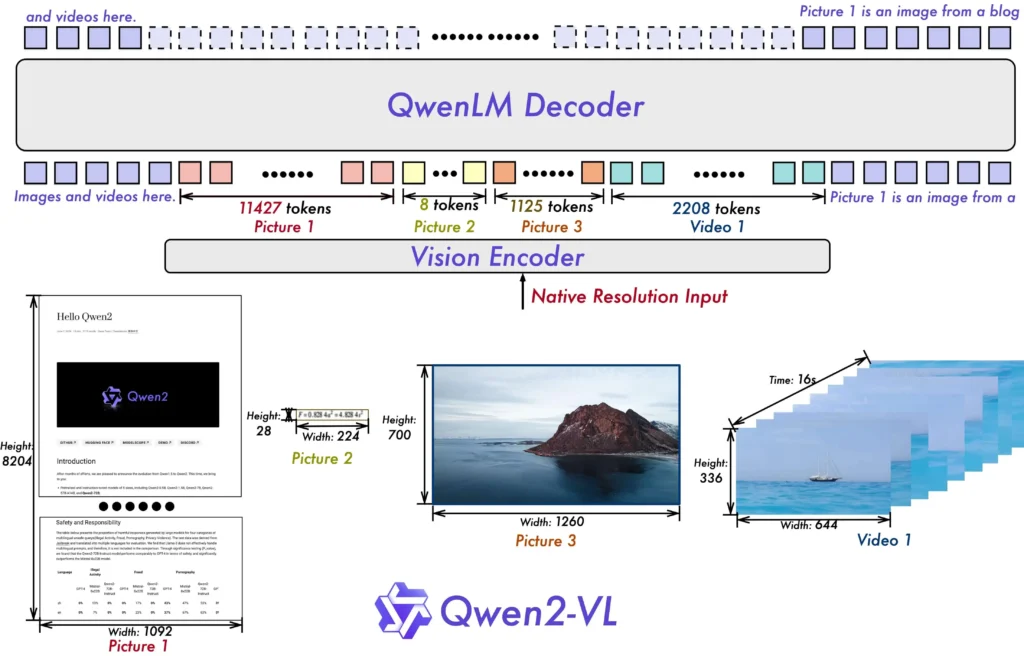
Naive Dynamische Auflösung: Im Gegensatz zu früher kann Qwen2-VL beliebige Bildauflösungen verarbeiten und sie in eine dynamische Anzahl von visuellen Tokens umwandeln, was eine menschenähnlichere visuelle Verarbeitungserfahrung bietet.
naive-dynamische-aufloesung
Multimodale Rotations-Positionseinbettung (M-ROPE): Zerlegt die Positionseinbettung in Teile, um eindimensionale textuelle, zweidimensionale visuelle und dreidimensionale Video-Positionsinformationen zu erfassen, was die multimodalen Verarbeitungsfähigkeiten verbessert.
multimodale-rotations-positionseinbettung
Außerdem betont das Modell die zunehmende Bedeutung von Multimodalmodellen in der KI-Forschung. Diese Modelle kombinieren Text, Bild und anderen Datentypen, um umfassende Analysen durchzuführen. Da sich der Markt und die Anwendungsfälle weiter diversifizieren, ist klar, dass es entscheidend sein wird, solche All-in-One-Modelle zu entwickeln, um den Anforderungen gerecht zu werden.
Qwen-2VLs Zusammenfassung des Videos:
Das Video beginnt mit einem Mann, der in die Kamera spricht, gefolgt von einer Gruppe von Menschen, die in einem Kontrollraum sitzen. Die Kamera schwenkt dann zu zwei Männern, die in einer Raumstation schweben und in die Kamera sprechen. Die Männer scheinen Astronauten zu sein und tragen Raumanzüge. Die Raumstation ist mit verschiedenen Geräten und Maschinen gefüllt, und die Kamera schwenkt umher, um die verschiedenen Bereiche der Station zu zeigen. Die Männer sprechen weiterhin in die Kamera und scheinen ihre Mission und die verschiedenen Aufgaben, die sie durchführen, zu besprechen. Insgesamt bietet das Video einen faszinierenden Einblick in die Welt der Weltraumforschung und den Alltag von Astronauten.
Insgesamt zeigt die Einführung des Qwen2-VL-Modells von Alibaba erneut, dass die Grenze des Machbaren in der KI stetig erweitert wird. Dies könnte eine Lawine weiterer Innovationen auslösen und den Wettbewerb innerhalb der Branche beleben. Profis und Unternehmen sollten diese Entwicklung aufmerksam verfolgen und darüber diskutieren, wie solche Technologien in ihren eigenen Arbeitsfeldern integriert werden können.
Zusammenfassung
Alibaba hat Qwen2-VL-Modell vorgestellt, das Videos über 20 Minuten analysieren kann.
Das Modell fasst Inhalte zusammen und beantwortet Fragen dazu.
Dies revolutioniert die Bild- und Videoanalyse und hat weitreichende Implikationen.
Betont die Bedeutung von Multimodalmodellen in der KI-Forschung.
Wird voraussichtlich eine Welle weiterer Innovationen und Wettbewerbe in der Branche auslösen.
Florian Schröder ist Experte im Online-Marketing mit Schwerpunkt PPC (Pay-Per-Click) Kampagnen. Die revolutionären Möglichkeiten der KI erkennt er nicht nur, sondern hat sie bereits fest in seine tägliche Arbeit integriert, um innovative und effektive Marketingstrategien zu entwickeln.
Er ist überzeugt davon, dass die Zukunft des Marketings untrennbar mit der Weiterentwicklung und Nutzung von künstlicher Intelligenz verbunden ist und setzt sich dafür ein, stets am Puls dieser technologischen Entwicklungen zu bleiben.
Wir verwenden Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wir tun dies, um das Surferlebnis zu verbessern und um personalisierte Werbung anzuzeigen. Wenn Sie diesen Technologien zustimmen, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn Sie Ihre Zustimmung nicht erteilen oder zurückziehen, können bestimmte Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.